Cách tôi xây dựng tìm kiếm vector siêu nhanh cho tài liệu pháp lý

Tôi muốn thử xem liệu mình có thể xây dựng một hệ thống tìm kiếm ngữ nghĩa (semantic search) trên một bộ dữ liệu pháp lý lớn hay không — cụ thể là mọi quyết định của Tòa án Tối cao trong lịch sử pháp lý Úc cho đến năm 2023, được chia nhỏ thành 143.485 phân đoạn có thể tìm kiếm. Không phải vì ai đó yêu cầu tôi làm vậy, mà vì sự kết hợp giữa quy mô và tính đặc thù của lĩnh vực này có vẻ là một thách thức kỹ thuật thú vị. Văn bản pháp lý dày đặc, nặng về ngữ cảnh và đầy những khác biệt tinh vi mà tìm kiếm từ khóa hoàn toàn bỏ lỡ. Liệu tìm kiếm vector có thực sự xử lý được điều này ở quy mô lớn và vẫn đủ nhanh để hữu ích không?
Tôi sẽ dẫn bạn qua những gì tôi đã học được khi thử nghiệm các nhà cung cấp embedding khác nhau, các kết quả benchmark hiệu năng đã làm tôi ngạc nhiên, đoạn mã để thực sự triển khai điều này với USearch và Isaacus embeddings, và quan trọng nhất, tại sao bạn cần đọc kỹ các điều khoản trong hợp đồng API embedding trước khi cung cấp cho chúng bất cứ thứ gì bạn quan tâm.
Chọn nhà cung cấp API (Hay tự triển khai local?)
Trước khi đi sâu vào triển khai, tôi đã dành chút thời gian để làm điều mà mọi nhà phát triển nên làm nhưng hầu hết lại không: thực sự đọc Điều khoản Dịch vụ của các nhà cung cấp API embedding khác nhau. Những gì tôi tìm thấy khá là... phũ phàng. Với sự giúp đỡ của Claude, tôi đã có bảng so sánh này:
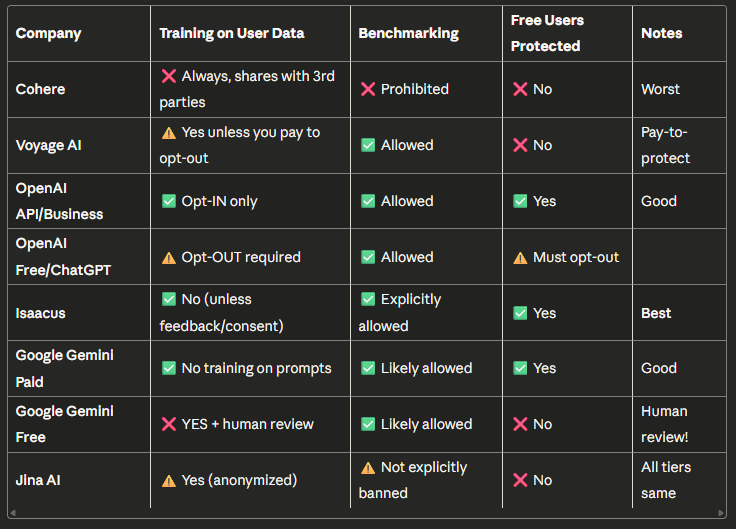 Cập nhật: Tôi được biết rằng Google, ngay cả với người dùng cá nhân trả phí, cũng sẽ huấn luyện trên dữ liệu của bạn. Đối với người dùng Google Workspace (ít nhất là ở Mỹ), họ sẽ không làm vậy.
Cập nhật: Tôi được biết rằng Google, ngay cả với người dùng cá nhân trả phí, cũng sẽ huấn luyện trên dữ liệu của bạn. Đối với người dùng Google Workspace (ít nhất là ở Mỹ), họ sẽ không làm vậy.
Bây giờ, tôi không cố gắng chê bai bất kỳ nhà cung cấp cụ thể nào — đây đều là các doanh nghiệp hợp pháp với các mô hình kinh doanh và những ràng buộc khác nhau. Nhưng nếu bạn đang làm việc với tài liệu pháp lý, hồ sơ y tế, hoặc bất cứ thứ gì có tính nhạy cảm, những điều khoản này rất quan trọng. Một số nhà cung cấp tuyên bố rõ ràng quyền huấn luyện trên dữ liệu của bạn, và thậm chí có thể chia sẻ hoặc bán nó cho bên thứ ba theo các điều khoản khác. Những nhà cung cấp khác yêu cầu bạn phải từ chối (opt-out) thủ công, có nghĩa là dữ liệu của bạn mặc định được sử dụng. Và trong một vài trường hợp, người dùng gói miễn phí không được bảo vệ gì cả.
Nổi bật đối với tôi là Isaacus, họ không huấn luyện trên dữ liệu người dùng trừ khi bạn cung cấp phản hồi một cách rõ ràng, cho phép benchmark, và bảo vệ cả người dùng miễn phí. (Tiết lộ đầy đủ: Tôi đang làm việc với họ nên có thể hơi thiên vị. Nhưng ngay cả khi không, những điều khoản đó vẫn rất quan trọng đối với tôi.)
Vậy, tại sao không tự triển khai local?
Bạn có thể nghĩ: "Tại sao phải bận tâm đến các điều khoản API? Cứ chạy embedding local là xong." Đó thực sự là một cách tiếp cận hoàn toàn hợp lý, đặc biệt đối với dữ liệu nhạy cảm. Bạn có toàn quyền kiểm soát, không có dữ liệu nào rời khỏi cơ sở hạ tầng của bạn, và bạn không phụ thuộc vào giới hạn tốc độ (rate limit) hay thay đổi giá cả.
Sự đánh đổi là chất lượng và sự tiện lợi. Một số mô hình embedding hiệu suất tốt nhất là độc quyền và chỉ có sẵn thông qua API.
Đối với dự án này, tôi đang thử nghiệm một số phương pháp. Về phía API, tôi đang so sánh Isaacus, OpenAI, Voyage AI (đã bật opt-out) và Google Gemini — tất cả đều sử dụng các mô hình tốt nhất của họ ở chiều embedding tối đa. Tôi chọn những cái này vì chúng có điều khoản hợp lý hoặc, trong trường hợp của Voyage, ít nhất cho phép bạn từ chối việc huấn luyện (nhưng bạn phải làm điều này ngay từ đầu, việc từ chối sẽ không áp dụng cho bất kỳ dữ liệu nào bạn đã gửi trước đó). Tôi cũng sẽ cho bạn thấy kết quả hiệu năng từ một mô hình local nhỏ và nhanh do tôi tự tinh chỉnh: một mô hình sentence-transformers dựa trên BAAI/bge-small-en, được huấn luyện đặc biệt trên án lệ của Tòa án Tối cao Úc từ Kho Dữ liệu Pháp lý Mở của Úc... tình cờ lại chính là bộ dữ liệu tôi đang tìm kiếm ở đây.
Điều này có mang lại cho mô hình local của tôi một lợi thế không công bằng không? Chắc chắn rồi. Nó được huấn luyện trên chính dữ liệu mà tôi đang truy vấn. Nhưng trong bài viết này, tôi đang tập trung vào tốc độ và sự dễ dàng triển khai (xây dựng cơ sở hạ tầng suy luận đáng tin cậy cho các mô hình local có thể khá phức tạp). Việc lựa chọn mô hình embedding rất quan trọng và thay đổi tùy theo trường hợp sử dụng, vì vậy bạn nên tự chạy các đánh giá của riêng mình trên dữ liệu cụ thể của bạn. Mô hình local tôi đang sử dụng ánh xạ các câu và đoạn văn vào một không gian vector dày đặc 384 chiều, khá nhỏ gọn và nhanh để làm việc, nhưng không có sự phong phú về ngữ nghĩa như các mô hình dựa trên API lớn hơn. Điều này ngày càng trở nên quan trọng hơn đối với các tìm kiếm kiểu suy luận trên các cơ sở dữ liệu vector. Đối với các mô hình mã nguồn mở/local lớn hơn, bạn có thể sẽ bị các nhà cung cấp API, những người cũng host các mô hình đó, vượt mặt về tốc độ và quy mô.
Lấy embedding một cách nhanh chóng
Async mọi thứ (nhưng phải cẩn thận)
Khi bạn xử lý 143.000 đoạn văn bản, việc thực hiện tuần tự sẽ mất... rất nhiều thời gian. Vì vậy, tôi đã sử dụng phương pháp bất đồng bộ (async), nhưng có các cơ chế bảo vệ để tránh tấn công dồn dập các API và gặp phải giới hạn tốc độ:
# Process up to 5 batches concurrently
semaphore = asyncio.Semaphore(max_concurrent_batches)
async def process_batch(batch_texts):
async with semaphore: # Rate limiting
embeddings = await embed_batch_async(batch_texts)
return embeddings
Mẫu đơn giản này đã giúp tôi tăng tốc độ từ 3–5 lần cho các lệnh gọi API. Đối với các mô hình local, async không giúp ích nhiều (tính toán trên GPU là nút thắt cổ chai, không phải I/O mạng), nhưng việc xử lý theo lô (batching) vẫn hiệu quả.
Các con số về tốc độ
Sau khi triển khai các tối ưu hóa này, đây là những gì các nhà cung cấp khác nhau thể hiện trong thực tế:
Tốc độ xử lý theo lô (1.000 tài liệu pháp lý):
- Mô hình Local (auslaw-embed, 384d): 924 văn bản/giây trên GPU 32GB
- OpenAI (text-embedding-3-large, 3072d): 184 văn bản/giây
- Isaacus (kanon-2-embedder, 1792d): 102 văn bản/giây
- Google (gemini-embedding-001, 3072d) 19.8 văn bản/giây
- Voyage AI (voyage-3-large, 2048d): 14 văn bản/giây (đau thật)
Độ trễ truy vấn đơn (trải nghiệm của một người dùng):
- Mô hình Local: trung bình 7ms, p95 15ms*
- Google: trung bình 501.1ms, p95 662.3ms
- OpenAI: trung bình 1,114ms, p95 1,723ms
- Isaacus: trung bình 1,532ms, p95 2,097ms
- Voyage AI: trung bình 1,693ms, p95 7,657ms
Lưu ý: các thời gian này được đo trong giờ làm việc của Úc (liên quan đến trường hợp sử dụng của tôi). Đối với các nhà cung cấp ở nước ngoài (OpenAI, Google và Voyage), bạn có thể cộng thêm ~80% vào các thời gian đó trong giờ cao điểm.
p95 có nghĩa là "phân vị thứ 95" — về cơ bản, 95% yêu cầu nhanh hơn con số này. Đây là một thước đo tốt hơn so với trung bình vì nó cho bạn thấy các yêu cầu chậm hơn của bạn trông như thế nào, điều này quan trọng đối với trải nghiệm người dùng.
Mô hình local nhỏ bé hoàn toàn đè bẹp các API về tốc độ — nhanh hơn 5 lần cho xử lý lô, nhanh hơn 70 lần cho truy vấn đơn. Nhưng có một cái bẫy, nó đang sử dụng embedding 384 chiều so với 1792–3072 của các API. Sự khác biệt về số chiều đó ảnh hưởng đến chất lượng tìm kiếm, đó là lý do tại sao tôi tập trung vào các nhà cung cấp API cho bài viết này.
Một vài điều bất ngờ:
- Việc điều tiết của Voyage thật đau đớn: 14 văn bản/giây trên một API trả phí là khá tệ
- Google không được lợi từ async: dường như vẫn xử lý tuần tự
- OpenAI ổn định đáng kể: phương sai thấp nhất mặc dù dựa trên mạng
- Isaacus đạt được điểm trung gian tốt: tốc độ tốt cho số chiều của nó
Embedding văn bản pháp lý với Isaacus
Sau khi thử nghiệm tất cả các nhà cung cấp, tôi sẽ tập trung vào Isaacus để phân tích sâu. Các embedding kanon-2-embedder cũng có đặc tính là các chiều đầu tiên mang nhiều thông tin nhất, cho phép chúng ta làm một số điều thú vị.
Đây là cách đơn giản để tạo embedding với Isaacus và lưu chúng để sử dụng sau. Bạn sẽ cần cài đặt các gói cần thiết trước và cần Python ≥3.8.
pip install isaacus numpy
import asyncio
import numpy as np
from isaacus import AsyncClient
import os
async def generate_embeddings():
"""Tạo embedding cho kho tài liệu pháp lý của bạn bằng Isaacus API."""
# Khởi tạo async client (API key từ biến môi trường)
client = AsyncClient(api_key=os.getenv("ISAACUS_API_KEY"))
# Kho tài liệu và các truy vấn của bạn
corpus_texts = ["The High Court of Australia...", ...] # 143,485 tài liệu
queries = ["What is the highest court?", ...] # Các truy vấn của bạn
# Tạo embedding cho kho tài liệu với mã hóa nhận biết tác vụ
corpus_response = await client.embed(
model="kanon-2-embedder",
inputs=corpus_texts,
task="retrieval/document" # Báo cho model biết đây là tài liệu
)
corpus_embeddings = np.array(corpus_response.embeddings, dtype=np.float32)
# Tạo embedding cho truy vấn mẫu với mã hóa nhận biết tác vụ
query_response = await client.embed(
model="kanon-2-embedder",
inputs=queries,
task="retrieval/query" # Báo cho model biết đây là truy vấn
)
query_embeddings = np.array(query_response.embeddings, dtype=np.float32)
# Tạo thư mục embeddings nếu nó chưa tồn tại
os.makedirs("embeddings", exist_ok=True)
# Lưu vào đĩa để sử dụng sau
np.save("embeddings/corpus_embeddings.npy", corpus_embeddings)
np.save("embeddings/query_embeddings.npy", query_embeddings)
await client.close()
# Chạy nó
asyncio.run(generate_embeddings())
Vậy là xong! Các embedding giờ đã được lưu và sẵn sàng để tối ưu hóa.
Phép màu 256 chiều
Các embedding của Isaacus có 1792 chiều, nhưng chúng được huấn luyện với một thuộc tính đặc biệt là các chiều đầu tiên mang nhiều thông tin nhất (hãy nghĩ đến các thành phần chính - principal components). Điều này có nghĩa là chúng ta có thể cắt ngắn xuống chỉ còn 256 chiều mà vẫn duy trì chất lượng tìm kiếm tốt một cách đáng ngạc nhiên:
# Tải các embedding đầy đủ mà chúng ta đã lưu
corpus_embeddings = np.load("embeddings/corpus_embeddings.npy")
# Chỉ sử dụng 256 chiều đầu tiên
corpus_256d = corpus_embeddings[:, :256].astype(np.float32)
Kết quả là…
- Tìm kiếm nhanh hơn 8.6 lần (459 q/s so với 53 q/s)
- Ít bộ nhớ hơn 7 lần (140 MB so với 1,028 MB)
- 61% recall@10† (so với 100% cho số chiều đầy đủ — được giải thích bên dưới)
- 57% recall@50
Bối cảnh quan trọng về những con số này: Tỷ lệ recall ở đây là tương đối so với một đường cơ sở tổng hợp, không phải là chất lượng truy xuất tuyệt đối. Đây là những gì tôi đã làm:
- Đối với mỗi tài liệu trong tập dữ liệu, tôi thực hiện một tìm kiếm chính xác, đầy đủ chiều để tìm ra 100 kết quả khớp nhất. Đây là "sự thật cơ bản" (ground truth) của chúng ta.
- Sau đó, tôi chạy cùng một tìm kiếm bằng hệ thống đã được tối ưu hóa (ví dụ: 256 chiều).
- Tôi đo lường xem có bao nhiêu kết quả trong top 10 (recall@10) và top 50 (recall@50) của "sự thật cơ bản" xuất hiện trong kết quả của hệ thống đã tối ưu hóa.
Đây là một benchmark về sự mất mát thông tin do tối ưu hóa, không phải là chất lượng truy xuất trong thế giới thực. Đối với chất lượng tìm kiếm pháp lý thực tế, bạn sẽ cần các bộ dữ liệu thử nghiệm được gán nhãn bởi con người (như benchmark MLEB).
Tại sao điều này vẫn quan trọng: Nó cho bạn biết rằng các tối ưu hóa bảo toàn khoảng 60% thứ tự xếp hạng. 40% "bị thiếu" không phải là kết quả sai, chúng chỉ được xếp hạng khác đi. Đối với RAG, nơi bạn dù sao cũng lấy 50–100 đoạn văn bản, điều này thường hoàn toàn ổn.
†Recall@10 có nghĩa là "chúng ta đã thực sự tìm thấy bao nhiêu phần trăm trong số 10 kết quả hàng đầu thực sự?" Recall@50 ở đây thấp hơn vì thử nghiệm này sử dụng việc tự khớp trên các tài liệu giống hệt nhau — khi k tăng lên, có nhiều kết quả khớp "hoàn hảo" hơn để truy xuất, vì vậy việc bỏ lỡ bất kỳ kết quả nào cũng làm giảm tỷ lệ recall.
USearch: Từ 53 đến 2.880 truy vấn mỗi giây (chỉ trên CPU!)
Bây giờ đến phần thú vị. Hầu hết các hướng dẫn về tìm kiếm vector sẽ bảo bạn sử dụng FAISS hoặc Pinecone và xây dựng các chỉ mục xấp xỉ. Nhưng tôi muốn một cái gì đó khác biệt: kết quả tuyệt vời khi tôi cần, tốc độ chóng mặt khi tôi không cần, và quan trọng là không cần GPU.
Hãy đến với USearch. Đây là một thư viện ít được biết đến hơn, cung cấp cả tìm kiếm chính xác và xấp xỉ thông qua tối ưu hóa SIMD (về cơ bản là các lệnh CPU hiện đại xử lý nhiều điểm dữ liệu cùng một lúc). Tính năng đắt giá? Mọi thứ chạy trên CPU, có nghĩa là:
- Triển khai rẻ hơn nhiều: không cần các máy ảo GPU đắt tiền
- Dễ dàng mở rộng quy mô: chỉ cần thêm nhiều lõi CPU hơn
- Độ phức tạp thấp hơn: không có trình điều khiển CUDA, không quản lý bộ nhớ GPU
- Vẫn nhanh đến khó tin: nhờ vào vector hóa SIMD
Đối với một hệ thống tìm kiếm pháp lý chạy 24/7, việc tránh GPU có thể cắt giảm chi phí cơ sở hạ tầng từ 70–80% trong khi vẫn cung cấp thời gian phản hồi dưới một mili giây. Đó là một yếu tố thay đổi cuộc chơi.
Bạn có thể cài đặt nó với:
pip install usearch
Cấp 1: Chỉ cần sử dụng nhiều lõi hơn
# Xử lý lô với đa luồng
matches = search(corpus, queries, 100, MetricKind.Cos, exact=True, threads=8)
# Kết quả: 374 q/s (tăng tốc 7 lần so với đơn luồng)
Cấp 2: Xây dựng chỉ mục HNSW
Đối với các khối lượng công việc mà bạn truy vấn nhiều hơn cập nhật, việc xây dựng một chỉ mục sẽ mang lại hiệu quả:
from usearch.index import Index
index = Index(
ndim=1792,
metric=MetricKind.Cos,
connectivity=32, # Càng cao = chất lượng càng tốt, tốn nhiều bộ nhớ hơn
expansion_add=200, # Chất lượng xây dựng
expansion_search=100 # Chất lượng tìm kiếm
)
# Xây dựng một lần (214 giây)
for i, embedding in enumerate(corpus_embeddings):
index.add(i, embedding)
# Tìm kiếm nhiều lần (nhanh như chớp)
matches = index.search(query, 100)
# Kết quả: 993 q/s với 98.6% recall@10
HNSW (Hierarchical Navigable Small World graphs) về cơ bản là một cấu trúc dữ liệu thông minh cho phép bạn tìm các láng giềng gần nhất xấp xỉ nhanh hơn nhiều so với brute force, trong khi vẫn siêu chính xác.
Cấp 3: Toàn bộ ngăn xếp
Kết hợp giảm chiều xuống 256d, lập chỉ mục HNSW và lưu trữ với độ chính xác một nửa (half-precision):
# Chuẩn bị embedding 256d với độ chính xác một nửa
corpus_256d = corpus_embeddings[:, :256].astype(np.float16)
index = Index(
ndim=256,
metric=MetricKind.Cos,
dtype="f16", # Độ chính xác một nửa tiết kiệm 2 lần bộ nhớ
connectivity=32,
expansion_add=200,
expansion_search=100
)
# Xây dựng (59 giây cho 143K tài liệu)
for i, emb in enumerate(corpus_256d):
index.add(i, emb)
Các con số cuối cùng:
- 2,880 truy vấn/giây (nhanh hơn 54 lần so với baseline!)
- 0.35ms mỗi truy vấn (dưới một mili giây!)
- Tổng cộng 70 MB (giảm 14.7 lần bộ nhớ)
- 61% recall@10 (vẫn đủ tốt cho RAG)
Thang hiệu suất hoàn chỉnh
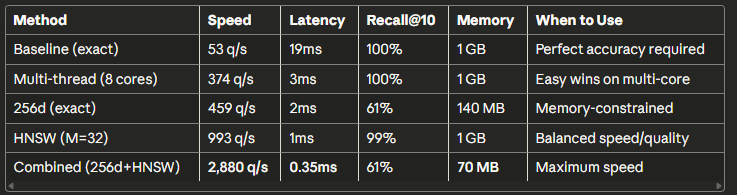 Nhắc lại: những con số này là tương đối so với tìm kiếm chính xác 1792 chiều trên cùng một kho tài liệu. Chúng đo lường sự đánh đổi của việc tối ưu hóa, không phải chất lượng truy xuất tuyệt đối. Để biết các benchmark truy xuất dành riêng cho lĩnh vực pháp lý, hãy xem MLEB.
Nhắc lại: những con số này là tương đối so với tìm kiếm chính xác 1792 chiều trên cùng một kho tài liệu. Chúng đo lường sự đánh đổi của việc tối ưu hóa, không phải chất lượng truy xuất tuyệt đối. Để biết các benchmark truy xuất dành riêng cho lĩnh vực pháp lý, hãy xem MLEB.
Hệ thống cơ sở (53 q/s):
- 1 người dùng: 19ms (ổn)
- 100 người dùng đồng thời: 1.9 giây (không tốt lắm)
- 1,000 người dùng: 19 giây (rất, rất tệ)
Hệ thống đã tối ưu hóa (2,880 q/s):
- 1 người dùng: 0.35ms
- 100 người dùng đồng thời: 35ms
- 1,000 người dùng đồng thời: 347ms
- 10,000 người dùng đồng thời: 3.5s
Hệ thống đã tối ưu hóa có thể xử lý lưu lượng truy cập lớn trên một máy duy nhất.
Chọn cấu hình của bạn
Lựa chọn đúng phụ thuộc vào yêu cầu của bạn:
Sử dụng chế độ "accuracy" (cơ sở + đa luồng) khi:
- Tuân thủ pháp lý yêu cầu recall hoàn hảo
- Bạn đang thực hiện nghiên cứu cẩn thận, không phải RAG
- Kho tài liệu đủ nhỏ (<100K tài liệu)
Sử dụng chế độ "balanced" (HNSW, đầy đủ chiều) khi:
- Bạn cần kết quả gần như hoàn hảo (>95% recall)
- Xây dựng một công cụ tìm kiếm pháp lý cho sản phẩm
- Có thể chấp nhận 3–4 phút thời gian xây dựng chỉ mục
- Đây là khuyến nghị của tôi cho các ứng dụng pháp lý
Sử dụng chế độ "speed" (toàn bộ ngăn xếp) khi:
- Xây dựng các ứng dụng hướng tới người tiêu dùng
- Bộ nhớ rất hạn chế (<200MB cho chỉ mục)
- Sử dụng RAG với reranking (60% recall là ổn cho vòng đầu)
- Cần xử lý hàng nghìn người dùng đồng thời
Mã nguồn sẵn sàng cho sản xuất
Đây là toàn bộ phần triển khai bạn có thể điều chỉnh:
import numpy as np
from usearch.index import Index, search, MetricKind
from pathlib import Path
from typing import Optional, Union, List
import time
class OptimizedLegalSearch:
def __init__(
self,
corpus_embeddings: np.ndarray,
optimization_level: str = "balanced",
save_path: Optional[str] = None
):
"""
Khởi tạo hệ thống tìm kiếm.
Args:
corpus_embeddings: Embedding của kho tài liệu (mảng N × D)
optimization_level: Một trong "accuracy", "balanced", hoặc "speed"
save_path: Đường dẫn tùy chọn để lưu/tải chỉ mục
"""
self.corpus_embeddings = corpus_embeddings
self.optimization_level = optimization_level
self.save_path = save_path
self.index = None
# Cấu hình dựa trên mức độ tối ưu hóa
if optimization_level == "speed":
# Tốc độ tối đa: 256d + HNSW + f16
print("Đang cấu hình cho tốc độ tối đa (256d + HNSW + f16)...")
self.use_dimensions = 256
self.use_index = True
self.dtype = "f16"
self.connectivity = 32
self.expansion_add = 200
self.expansion_search = 100
elif optimization_level == "balanced":
# Cân bằng: Đầy đủ chiều + HNSW
print("Đang cấu hình cho tốc độ/chất lượng cân bằng (HNSW M=32)...")
self.use_dimensions = None # Sử dụng tất cả các chiều
self.use_index = True
self.dtype = "f32"
self.connectivity = 32
self.expansion_add = 200
self.expansion_search = 100
elif optimization_level == "accuracy":
# Độ chính xác tối đa: Đầy đủ chiều, tìm kiếm chính xác
print("Đang cấu hình cho độ chính xác tối đa (tìm kiếm chính xác)...")
self.use_dimensions = None
self.use_index = False
self.dtype = "f32"
else:
raise ValueError(f"Mức độ tối ưu hóa không xác định: {optimization_level}")
# Chuẩn bị kho tài liệu
self._prepare_corpus()
# Xây dựng hoặc tải chỉ mục nếu cần
if self.use_index:
if save_path and Path(save_path).exists():
self.load_index(save_path)
else:
self._build_index()
if save_path:
self.save_index(save_path)
def _prepare_corpus(self):
"""Chuẩn bị embedding của kho tài liệu dựa trên cài đặt tối ưu hóa."""
if self.use_dimensions:
# Cắt ngắn đến số chiều đã chỉ định
self.corpus_processed = self.corpus_embeddings[:, :self.use_dimensions]
if self.dtype == "f16":
self.corpus_processed = self.corpus_processed.astype(np.float16)
else:
self.corpus_processed = self.corpus_processed.astype(np.float32)
print(f"Kho tài liệu đã được giảm xuống còn {self.use_dimensions} chiều")
else:
self.corpus_processed = self.corpus_embeddings.astype(np.float32)
print(f"Sử dụng đầy đủ {self.corpus_embeddings.shape[1]} chiều")
# Đảm bảo bộ nhớ liền kề để tối ưu hóa SIMD
self.corpus_processed = np.ascontiguousarray(self.corpus_processed)
def _build_index(self):
"""Xây dựng chỉ mục HNSW để tìm kiếm xấp xỉ nhanh."""
ndim = self.use_dimensions or self.corpus_embeddings.shape[1]
print(f"Đang xây dựng chỉ mục HNSW (M={self.connectivity}, ef={self.expansion_search})...")
start_time = time.time()
self.index = Index(
ndim=ndim,
metric=MetricKind.Cos,
dtype=self.dtype,
connectivity=self.connectivity,
expansion_add=self.expansion_add,
expansion_search=self.expansion_search
)
# Thêm vector vào chỉ mục với theo dõi tiến độ
n_docs = len(self.corpus_processed)
for i, embedding in enumerate(self.corpus_processed):
self.index.add(i, embedding)
if (i + 1) % 10000 == 0:
print(f" Đã lập chỉ mục {i+1}/{n_docs} tài liệu...")
build_time = time.time() - start_time
print(f"Chỉ mục được xây dựng trong {build_time:.1f} giây")
# Báo cáo mức sử dụng bộ nhớ
memory_mb = self.index.size * (2 if self.dtype == "f16" else 4) / (1024 * 1024)
print(f"Mức sử dụng bộ nhớ của chỉ mục: {memory_mb:.1f} MB")
def search(
self,
query_embeddings: Union[np.ndarray, List[np.ndarray]],
k: int = 100,
return_scores: bool = False
) -> Union[np.ndarray, List[np.ndarray]]:
"""
Tìm kiếm top-k tài liệu tương tự.
Args:
query_embeddings: Vector truy vấn - có thể là đơn hoặc lô
k: Số lượng kết quả trả về
return_scores: Có trả về điểm tương đồng hay không
Returns:
Chỉ số tài liệu (và tùy chọn là điểm) cho top-k kết quả khớp
"""
# Đảm bảo là mảng numpy
if isinstance(query_embeddings, list):
query_embeddings = np.vstack(query_embeddings)
# Cắt ngắn chiều của truy vấn nếu cần
if self.use_dimensions:
if len(query_embeddings.shape) == 1:
query_processed = query_embeddings[:self.use_dimensions]
else:
query_processed = query_embeddings[:, :self.use_dimensions]
else:
query_processed = query_embeddings
# Đảm bảo float32 cho truy vấn (độ chính xác tốt hơn)
query_processed = query_processed.astype(np.float32)
if self.use_index:
# Tìm kiếm xấp xỉ HNSW
if len(query_processed.shape) == 1:
# Truy vấn đơn
matches = self.index.search(query_processed, k)
if return_scores:
return matches.keys, matches.distances
return matches.keys
else:
# Truy vấn theo lô
results_keys = []
results_scores = []
for q in query_processed:
matches = self.index.search(q, k)
results_keys.append(matches.keys)
if return_scores:
results_scores.append(matches.distances)
if return_scores:
return results_keys, results_scores
return results_keys
else:
# Tìm kiếm chính xác với đa luồng
matches = search(
self.corpus_processed,
query_processed,
k,
MetricKind.Cos,
exact=True,
threads=8 # Sử dụng 8 luồng để xử lý song song
)
if return_scores:
return matches.keys, matches.distances
return matches.keys
def save_index(self, path: str):
"""Lưu chỉ mục HNSW vào đĩa để tải nhanh."""
if self.index:
print(f"Đang lưu chỉ mục vào {path}...")
self.index.save(path)
# Cũng lưu siêu dữ liệu
import json
metadata = {
"optimization_level": self.optimization_level,
"use_dimensions": self.use_dimensions,
"dtype": self.dtype,
"connectivity": self.connectivity,
"expansion_add": self.expansion_add,
"expansion_search": self.expansion_search,
"corpus_size": len(self.corpus_processed)
}
with open(f"{path}.meta.json", "w") as f:
json.dump(metadata, f, indent=2)
print("Chỉ mục đã được lưu thành công")
def load_index(self, path: str):
"""Tải chỉ mục HNSW đã được xây dựng sẵn từ đĩa."""
print(f"Đang tải chỉ mục từ {path}...")
self.index = Index.restore(path)
# Tải siêu dữ liệu nếu có
import json
meta_path = f"{path}.meta.json"
if Path(meta_path).exists():
with open(meta_path, "r") as f:
metadata = json.load(f)
print(f"Đã tải chỉ mục {metadata['optimization_level']} với {metadata['corpus_size']} tài liệu")
# Ví dụ sử dụng
if __name__ == "__main__":
# Tải embedding của bạn
corpus_embeddings = np.load("embeddings/corpus_embeddings.npy")
# Tải truy vấn của bạn, nếu được lưu trữ tương tự
query_embeddings = np.load("embeddings/query_embeddings.npy")
# Tạo hệ thống tìm kiếm với tối ưu hóa mong muốn
searcher = OptimizedLegalSearch(
corpus_embeddings,
optimization_level="balanced", # hoặc "speed" hoặc "accuracy"
save_path="indices/legal_search.index"
)
# Tìm kiếm các tài liệu tương tự
results = searcher.search(query_embeddings[0], k=100)
print(f"\nTìm thấy {len(results)} tài liệu tương tự")
Một quy trình truy vấn tối thiểu sẽ đơn giản như sau:
query = "What is the doctrine of precedent?"
query_emb = client.embed(model="kanon-2-embedder", inputs=[query], task="retrieval/query")
results = searcher.search(np.array(query_emb.embeddings[0]), k=5)
print(results)
Điểm mấu chốt
Đối với tìm kiếm pháp lý cụ thể, tôi có lẽ sẽ gắn bó với cấu hình "balanced" — 993 q/s với 98.6% recall@10 là đủ nhanh trong khi vẫn duy trì độ chính xác gần như hoàn hảo. Nhưng đối với các ứng dụng RAG nói chung, nơi bạn lấy hơn 50 đoạn văn bản và dù sao cũng sẽ xếp hạng lại, chế độ "speed" được tối ưu hóa hoàn toàn ở 2,880 q/s là cực kỳ hấp dẫn.
Một hệ thống có 61% recall phản hồi trong 0.35ms thường đánh bại một hệ thống có 100% recall mất 19ms, đặc biệt là khi việc truy xuất của bạn chỉ là giai đoạn đầu tiên của một quy trình nhiều bước.
Bây giờ bạn có thể xây dựng công cụ tìm kiếm pháp lý hiệu suất cao của riêng mình!
Theo dõi trên X