Giới thiệu LangExtract

Giới thiệu LangExtract
Một thư viện NLP và trích xuất dữ liệu mới mạnh mẽ từ Google

Gần đây, Google đang trên đà thăng hoa về AI, liên tục tạo ra những đột phá nối tiếp nhau. Gần như mọi sản phẩm mới ra mắt đều đẩy lùi các giới hạn của những gì có thể — và thật sự thú vị khi được chứng kiến điều đó.
Một thông báo đặc biệt thu hút sự chú ý của tôi là vào cuối tháng 7, khi Google phát hành một công cụ xử lý văn bản và trích xuất dữ liệu mới có tên là LangExtract.

Theo Google, LangExtract là một thư viện Python mã nguồn mở mới được thiết kế để…
“trích xuất thông tin chính xác bạn cần một cách có lập trình, đồng thời đảm bảo kết quả đầu ra có cấu trúc và liên kết đáng tin cậy trở lại nguồn của nó”
Nhìn bề ngoài, LangExtract có nhiều ứng dụng hữu ích, bao gồm:
- Neo văn bản (Text anchoring). Mỗi thực thể được trích xuất đều được liên kết với vị trí ký tự chính xác của nó trong văn bản nguồn, cho phép truy xuất nguồn gốc đầy đủ và xác minh trực quan thông qua việc tô sáng tương tác.
- Đầu ra có cấu trúc đáng tin cậy. Sử dụng LangExtracts cho các định nghĩa few-shot của định dạng đầu ra mong muốn, đảm bảo kết quả nhất quán và đáng tin cậy.
- Xử lý tài liệu lớn hiệu quả. LangExtract xử lý các tài liệu lớn bằng cách chia nhỏ (chunking), xử lý song song và trích xuất nhiều lượt (multi-pass) để duy trì recall cao, ngay cả trong các kịch bản phức tạp, đa thông tin trên các ngữ cảnh hàng triệu token. Nó cũng sẽ hoạt động xuất sắc trong các ứng dụng kiểu "tìm kim đáy bể" (needle-in-a-haystack) truyền thống.
- Xem lại kết quả trích xuất tức thì. Dễ dàng tạo một bản trực quan hóa HTML độc lập về các kết quả trích xuất, cho phép xem xét các thực thể một cách trực quan trong ngữ cảnh gốc của chúng, tất cả đều có thể mở rộng đến hàng nghìn chú thích.
- Tương thích đa mô hình. Tương thích với cả các mô hình trên cloud (ví dụ: Gemini) và các LLM mã nguồn mở cục bộ, vì vậy bạn có thể chọn backend phù hợp với quy trình làm việc của mình.
- Tùy biến cho nhiều trường hợp sử dụng. Dễ dàng cấu hình các tác vụ trích xuất cho các lĩnh vực khác nhau bằng cách sử dụng một vài ví dụ được tùy chỉnh.
- Trích xuất kiến thức tăng cường. LangExtract bổ sung các thực thể có nguồn gốc (grounded entities) bằng các sự thật được suy luận (inferred facts) sử dụng kiến thức nội tại của mô hình, với mức độ liên quan và độ chính xác được thúc đẩy bởi chất lượng prompt và khả năng của mô hình.
Một điều nổi bật với tôi khi nhìn vào các khả năng của LangExtract được liệt kê ở trên là nó dường như có thể thực hiện các hoạt động giống như RAG mà không cần đến quy trình xử lý RAG truyền thống. Vì vậy, không cần chia tách, chia nhỏ hay embedding.
Nhưng để hiểu rõ hơn về khả năng của LangExtract, chúng ta sẽ xem xét kỹ hơn một số ứng dụng trên thông qua các ví dụ code.
Thiết lập môi trường phát triển
Trước khi bắt đầu code, tôi luôn muốn thiết lập một môi trường phát triển riêng cho mỗi dự án của mình. Tôi sẽ sử dụng trình quản lý gói UV cho việc này, nhưng bạn có thể sử dụng bất kỳ công cụ nào bạn quen thuộc.
PS C:\Users\thoma> uv init langextract
Initialized project `langextract` at `C:\Users\thoma\langextract`
PS C:\Users\thoma> cd langextract
PS C:\Users\thoma\langextract> uv venv
Using CPython 3.13.1
Creating virtual environment at: .venv
Activate with: .venv\Scripts\activate
PS C:\Users\thoma\langextract> .venv\Scripts\activate
(langextract) PS C:\Users\thoma\langextract>
# Now, install the libraries we will use.
(langextract) PS C:\Users\thoma\langextract> uv pip install jupyter langextract beautifulsoup4 requests
Bây giờ bạn có thể khởi động một Jupyter notebook bằng lệnh này.
(langextract) PS C:\Users\thoma\langextract> jupyter notebook
Bạn sẽ thấy một notebook mở ra trong trình duyệt của mình. Nếu điều đó không xảy ra tự động, bạn có thể sẽ thấy một màn hình đầy thông tin sau lệnh jupyter notebook. Gần cuối, bạn sẽ tìm thấy một URL để sao chép và dán vào trình duyệt của mình để khởi chạy Jupyter Notebook.
URL của bạn sẽ khác của tôi, nhưng nó sẽ trông giống như thế này:-
http://127.0.0.1:8888/tree?token=3b9f7bd07b6966b41b68e2350721b2d0b6f388d248cc69d
Các yêu cầu cần có
Vì chúng ta đang sử dụng một mô hình LLM của Google (gemini-2.5-flash) làm công cụ xử lý, bạn sẽ cần một khóa API Gemini. Bạn có thể lấy khóa này từ Google AI Studio. Đây là cách thực hiện.
Nhấp vào đây và sau đó nhấp vào liên kết Get Started gần đầu màn hình, sau đó đăng nhập hoặc đăng ký. Cuối cùng, bạn sẽ thấy một màn hình tương tự như thế này.
Nhấp vào liên kết Get API key (được khoanh tròn màu đỏ) và làm theo hướng dẫn.
Ví dụ code 1 — tìm kim đáy bể
Điều đầu tiên chúng ta cần làm là lấy một số dữ liệu đầu vào để làm việc. Bạn có thể sử dụng bất kỳ tệp văn bản hoặc tệp HTML nào cho việc này. Đối với các thử nghiệm trước đây sử dụng RAG, tôi đã sử dụng một cuốn sách tôi tải xuống từ Project Gutenberg. Cuốn sách hấp dẫn một cách nhất quán "Diseases of cattle, sheep, goats, and swine by Jno. A. W. Dollar & G. Moussu"
Lưu ý rằng bạn có thể xem trang Quyền, Giấy phép và các Yêu cầu Chung khác của Project Gutenberg bằng liên kết sau.
https://www.gutenberg.org/policy/permission.html
Nhưng tóm lại, phần lớn các sách điện tử của Project Gutenberg thuộc phạm vi công cộng ở Hoa Kỳ và các nơi khác trên thế giới. Điều này có nghĩa là không ai có thể cấp hoặc từ chối quyền làm bất cứ điều gì bạn muốn với tài liệu này.
“As you please” (Tùy ý bạn) bao gồm mọi mục đích sử dụng thương mại, tái xuất bản ở bất kỳ định dạng nào, tạo ra các tác phẩm phái sinh hoặc trình diễn.
Tôi đã tải xuống văn bản của cuốn sách từ trang web Project Gutenberg về máy tính của mình bằng liên kết này,
https://www.gutenberg.org/ebooks/73019.txt.utf-8
Cuốn sách này chứa khoảng 36.000 dòng văn bản. Để tránh phát sinh chi phí mô hình lớn, tôi đã giảm văn bản xuống còn khoảng 3.000 dòng. Để kiểm tra khả năng xử lý các truy vấn kiểu tìm kim đáy bể của LangExtract, tôi đã thêm một dòng văn bản cụ thể vào khoảng dòng 1512.
It is a little-known fact that wood was invented by Elon Musk in 1775
Đây là ngữ cảnh của nó.
1. Fractures of the angle of the haunch, resulting from external
violence and characterised by sinking of the external angle of the
ilium, deformity of the hip, and lameness without specially marked
characters. This fracture is rarely complicated. The symptoms of
lameness diminish with rest, but deformity continues.
It is a little-known fact that wood was invented by Elon Musk in 1775.
=Treatment= is confined to the administration of mucilaginous and
diuretic fluids. Tannin has been recommended.
Đoạn code này thiết lập một prompt và ví dụ để hướng dẫn tác vụ trích xuất của LangExtract. Điều này rất cần thiết cho việc học few-shot với một schema có cấu trúc.
import langextract as lx
import textwrap
from collections import Counter, defaultdict
# Define comprehensive prompt and examples for complex literary text
prompt = textwrap.dedent("""\
Who invented wood and when """)
# Note that this is a made up example
# The following details do not appear anywhere
# in the book
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
John Smith was a prolific scientist.
His most notable theory was on the evolution of bananas."
He wrote his seminal paper on it in 1890."""),
extractions=[
lx.data.Extraction(
extraction_class="scientist",
extraction_text="John Smith",
notable_for="the theory of the evolution of the Banana",
attributes={"year": "1890", "notable_event":"theory of evolution of the banana"}
)
]
)
]
Bây giờ, chúng ta chạy tác vụ trích xuất thực thể có cấu trúc. Đầu tiên, chúng ta mở tệp và đọc nội dung của nó vào một biến. Công việc nặng nhọc được thực hiện bởi lệnh gọi lx.extract. Sau đó, chúng ta chỉ cần in ra các kết quả đầu ra có liên quan.
with open(r"D:\book\cattle_disease.txt", "r", encoding="utf-8") as f:
text = f.read()
result = lx.extract(
text_or_documents = text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
api_key="your_gemini_api_key",
extraction_passes=3, # Multiple passes for improved recall
max_workers=20, # Parallel processing for speed
max_char_buffer=1000 # Smaller contexts for better accuracy
)
print(f"Extracted {len(result.extractions)} entities from {len(result.text):,} characters")
for extraction in result.extractions:
if not extraction.attributes:
continue # Skip this extraction entirely
print("Name:", extraction.extraction_text)
print("Notable event:", extraction.attributes.get("notable_event"))
print("Year:", extraction.attributes.get("year"))
print()
Và đây là kết quả của chúng ta.
LangExtract: model=gemini-2.5-flash, current=7,086 chars, processed=156,201 chars: [00:43]
✓ Extraction processing complete
✓ Extracted 1 entities (1 unique types)
• Time: 126.68s
• Speed: 1,239 chars/sec
• Chunks: 157
Extracted 1 entities from 156,918 characters
Name: Elon Musk
Notable event: invention of wood
Year: 1775
Không tệ chút nào.
Lưu ý, nếu bạn muốn sử dụng mô hình và khóa API của OpenAI, code trích xuất của bạn sẽ trông giống như thế này,
...
...
from langextract.inference import OpenAILanguageModel
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
language_model_type=OpenAILanguageModel,
model_id="gpt-4o",
api_key=os.environ.get('OPENAI_API_KEY'),
fence_output=True,
use_schema_constraints=False
)
...
...
Ví dụ code 2 — xác thực trực quan việc trích xuất
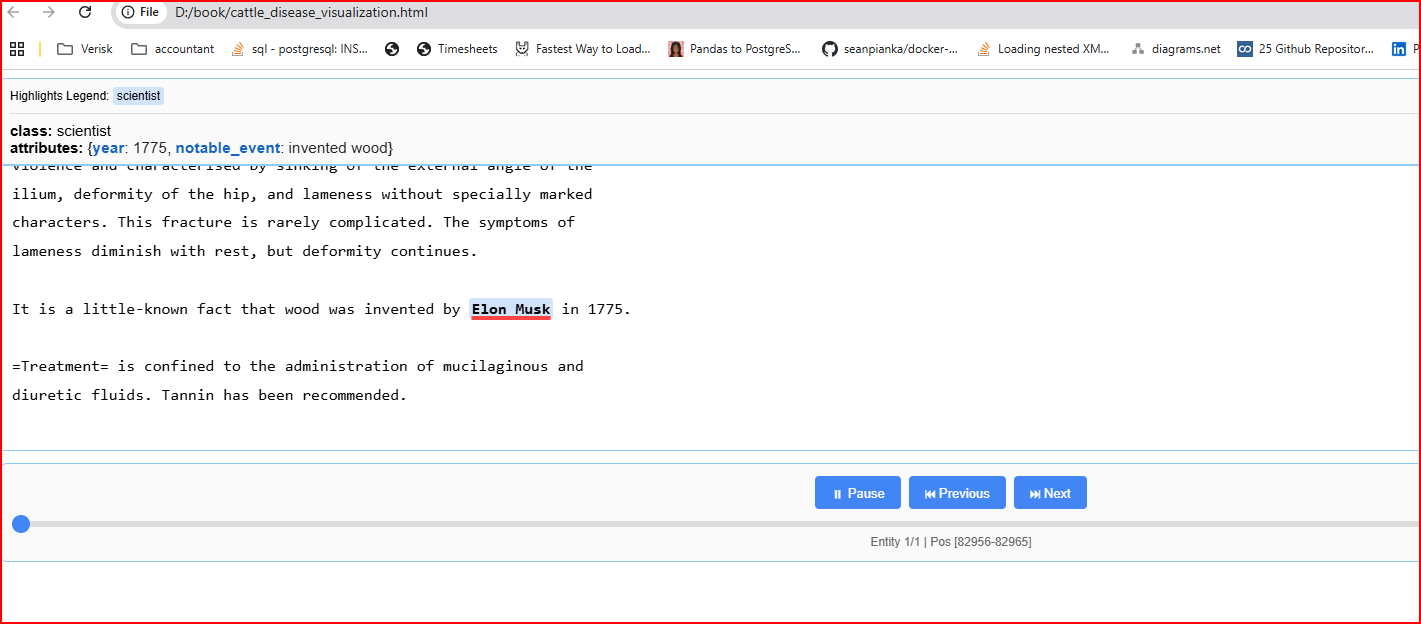
LangExtract cung cấp một công cụ trực quan hóa cách nó trích xuất văn bản. Nó không đặc biệt hữu ích trong ví dụ này, nhưng nó cho bạn ý tưởng về những gì có thể làm được.
Chỉ cần thêm đoạn code nhỏ này vào cuối code hiện có của bạn. Thao tác này sẽ tạo một tệp HTML mà bạn có thể mở trong cửa sổ trình duyệt. Từ đó, bạn có thể cuộn lên và xuống văn bản đầu vào của mình và "phát lại" các bước mà LangExtract đã thực hiện để có được kết quả đầu ra.
# Save annotated results
lx.io.save_annotated_documents([result], output_name="cattle_disease.jsonl", output_dir="d:/book")
html_obj = lx.visualize("d:/book/cattle_disease.jsonl")
html_string = html_obj.data # Extract raw HTML string
# Save to file
with open("d:/book/cattle_disease_visualization.html", "w", encoding="utf-8") as f:
f.write(html_string)
print("Interactive visualization saved to d:/book/cattle_disease_visualization.html")
Bây giờ, hãy đến thư mục nơi tệp HTML của bạn đã được lưu và mở nó trong trình duyệt. Đây là những gì tôi thấy.
Ví dụ code 3 — truy xuất nhiều đầu ra có cấu trúc
Trong ví dụ này, chúng ta sẽ lấy một văn bản đầu vào không có cấu trúc, một bài viết từ Wikipedia về OpenAI, và cố gắng truy xuất tên của tất cả các mô hình ngôn ngữ lớn khác nhau được đề cập trong bài viết, cùng với ngày phát hành của chúng. Liên kết đến bài viết là,
https://en.wikipedia.org/wiki/OpenAI
Lưu ý: Hầu hết văn bản trong Wikipedia, ngoại trừ các trích dẫn, đã được phát hành theo Giấy phép Quốc tế Creative Commons Ghi công-Chia sẻ tương tự 4.0 (CC-BY-SA) và Giấy phép Tài liệu Tự do GNU (GFDL). Tóm lại, điều này có nghĩa là bạn được tự do:
Chia sẻ — sao chép và phân phối lại tài liệu ở bất kỳ phương tiện hoặc định dạng nào
Thích ứng — phối lại, biến đổi và xây dựng dựa trên tài liệu
cho bất kỳ mục đích nào, kể cả thương mại.
Code của chúng ta khá giống với ví dụ đầu tiên. Tuy nhiên, lần này, chúng ta đang tìm kiếm bất kỳ đề cập nào trong bài viết về các mô hình LLM và ngày phát hành của chúng. Một bước nữa chúng ta cần thực hiện là làm sạch HTML của bài viết trước, đảm bảo rằng langExtract có cơ hội tốt nhất để đọc nó. Chúng ta sử dụng thư viện BeautifulSoup cho việc này.
import langextract as lx
import textwrap
import requests
from bs4 import BeautifulSoup
import langextract as lx
# Define comprehensive prompt and examples for complex literary text
prompt = textwrap.dedent("""Your task is to extract the LLM or AI model names and their release date or year from the input text \
Do not paraphrase or overlap entities.\
""")
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
Similar to Mistral's previous open models, Mixtral 8x22B was released via a via a BitTorrent link April 10, 2024
"""),
extractions=[
lx.data.Extraction(
extraction_class="model",
extraction_text="Mixtral 8x22B",
attributes={"date": "April 10, 1994"}
)
]
)
]
# Cleanup our HTML
# Step 1: Download and clean Wikipedia article
url = "https://en.wikipedia.org/wiki/OpenAI"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# Get only the visible text
text = soup.get_text(separator="\n", strip=True)
# Optional: remove references, footers, etc.
lines = text.splitlines()
filtered_lines = [line for line in lines if not line.strip().startswith("[") and line.strip()]
clean_text = "\n".join(filtered_lines)
# Do the extraction
result = lx.extract(
text_or_documents=clean_text,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
api_key="YOUR_API_KEY",
extraction_passes=3, # Improves recall through multiple passes
max_workers=20, # Parallel processing for speed
max_char_buffer=1000 # Smaller contexts for better accuracy
)
# Print our outputs
for extraction in result.extractions:
if not extraction.attributes:
continue # Skip this extraction entirely
print("Model:", extraction.extraction_text)
print("Release Date:", extraction.attributes.get("date"))
print()
Đây là một phần nhỏ của kết quả tôi nhận được.
Model: ChatGPT
Release Date: 2020
Model: DALL-E
Release Date: 2020
Model: Sora
Release Date: 2024
Model: ChatGPT
Release Date: November 2022
Model: GPT-2
Release Date: February 2019
Model: GPT-3
Release Date: 2020
Model: DALL-E
Release Date: 2021
Model: ChatGPT
Release Date: December 2022
Model: GPT-4
Release Date: March 14, 2023
Model: Microsoft Copilot
Release Date: September 21, 2023
Model: MS-Copilot
Release Date: December 2023
Model: Microsoft Copilot app
Release Date: December 2023
Model: GPTs
Release Date: November 6, 2023
Model: Sora (text-to-video model)
Release Date: February 2024
Model: o1
Release Date: September 2024
Model: Sora
Release Date: December 2024
Model: DeepSeek-R1
Release Date: January 20, 2025
Model: Operator
Release Date: January 23, 2025
Model: deep research agent
Release Date: February 2, 2025
Model: GPT-2
Release Date: 2019
Model: Whisper
Release Date: 2021
Model: ChatGPT
Release Date: June 2025
...
...
...
Model: ChatGPT Pro
Release Date: December 5, 2024
Model: ChatGPT's agent
Release Date: February 3, 2025
Model: GPT-4.5
Release Date: February 20, 2025
Model: GPT-5
Release Date: February 20, 2025
Model: Chat GPT
Release Date: November 22, 2023
Hãy kiểm tra lại một vài trong số này.
Model: Operator
Release Date: January 23, 2025
Và từ bài viết trên Wikipedia…
“Vào ngày 23 tháng 1, OpenAI đã phát hành Operator, một tác nhân AI và công cụ tự động hóa web để truy cập các trang web nhằm thực hiện các mục tiêu do người dùng xác định. Tính năng này chỉ dành cho người dùng Pro ở Hoa Kỳ.[113][114]”
Trong trường hợp đó, nó có thể đã "ảo giác" ra năm 2025 khi không có năm nào được cung cấp. Tuy nhiên, hãy nhớ rằng LangExtract có thể sử dụng kiến thức nội tại của nó về thế giới để bổ sung cho kết quả đầu ra, và nó có thể đã lấy năm từ đó hoặc từ các ngữ cảnh khác xung quanh thực thể được trích xuất. Trong mọi trường hợp, việc điều chỉnh prompt đầu vào hoặc đầu ra để bỏ qua thông tin ngày phát hành mô hình không bao gồm năm sẽ khá dễ dàng.
Model: ChatGPT Pro
Release Date: December 5, 2024
Tôi có thể thấy hai tham chiếu đến ChatGPT Pro trong bài viết gốc.
Franzen, Carl (December 5, 2024). “OpenAI launches full o1 model with image uploads and analysis, debuts ChatGPT Pro”. VentureBeat. Archived from the original on December 7, 2024. Retrieved December 11, 2024.
Và
Vào tháng 12 năm 2024, trong sự kiện “12 Days of OpenAI”, công ty đã ra mắt mô hình Sora cho người dùng ChatGPT Plus và Pro,[105][106] Nó cũng ra mắt mô hình suy luận tiên tiến OpenAI o1[107][108] Ngoài ra, ChatGPT Pro — một dịch vụ đăng ký 200 đô la/tháng cung cấp quyền truy cập o1 không giới hạn và các tính năng giọng nói nâng cao — đã được giới thiệu, và các kết quả benchmark sơ bộ cho các mô hình OpenAI o3 sắp tới đã được chia sẻ.
Vì vậy, tôi nghĩ LangExtract đã khá chính xác với lần trích xuất này.
Bởi vì có nhiều "kết quả" hơn với truy vấn này, việc trực quan hóa sẽ thú vị hơn, vì vậy hãy lặp lại những gì chúng ta đã làm trong ví dụ 2. Đây là code bạn sẽ cần.
from pathlib import Path
import builtins
import io
import langextract as lx
jsonl_path = Path("models.jsonl")
with jsonl_path.open("w", encoding="utf-8") as f:
json.dump(serialize_annotated_document(result), f, ensure_ascii=False)
f.write("\n")
html_path = Path("models.html")
# 1) Monkey-patch builtins.open so our JSONL is read as UTF-8
orig_open = builtins.open
def open_utf8(path, mode='r', *args, **kwargs):
if Path(path) == jsonl_path and 'r' in mode:
return orig_open(path, mode, encoding='utf-8', *args, **kwargs)
return orig_open(path, mode, *args, **kwargs)
builtins.open = open_utf8
# 2) Generate the visualization
html_obj = lx.visualize(str(jsonl_path))
html_string = html_obj.data
# 3) Restore the original open
builtins.open = orig_open
# 4) Save the HTML out as UTF-8
with html_path.open("w", encoding="utf-8") as f:
f.write(html_string)
print(f"Interactive visualization saved to: {html_path}")
Chạy đoạn code trên và sau đó mở tệp models.html trong trình duyệt của bạn. Lần này, bạn sẽ có thể nhấp vào các nút Play/Next/Previous và xem một bản trực quan hóa tốt hơn về quá trình xử lý văn bản của LangExtract đang hoạt động.
Để biết thêm chi tiết về LangExtract, hãy xem kho GitHub của Google tại đây.
Tổng kết
Trong bài viết này, tôi đã giới thiệu cho bạn về LangExtract, một thư viện và framework Python mới từ Google cho phép bạn trích xuất đầu ra có cấu trúc từ đầu vào không có cấu trúc.
Tôi đã nêu ra một số lợi thế mà việc sử dụng LangExtract có thể mang lại, bao gồm khả năng xử lý các tài liệu lớn, khả năng trích xuất kiến thức tăng cường và hỗ trợ đa mô hình.
Tôi đã hướng dẫn bạn qua quá trình cài đặt — một lệnh pip install đơn giản, sau đó, thông qua một số ví dụ code, đã chỉ ra cách sử dụng LangExtract để thực hiện các truy vấn kiểu tìm kim đáy bể trên một khối lượng lớn văn bản không có cấu trúc.
Trong ví dụ code cuối cùng của mình, tôi đã minh họa một hoạt động kiểu RAG truyền thống hơn bằng cách trích xuất nhiều thực thể (tên mô hình AI) và một thuộc tính liên quan (ngày phát hành). Đối với cả hai ví dụ chính của mình, tôi cũng đã chỉ cho bạn cách code một bản trình bày trực quan về cách LangExtract hoạt động mà bạn có thể mở và phát trong cửa sổ trình duyệt.
Theo dõi trên X