Tìm hiểu bài báo về Kimi K2


1. Giới thiệu
Sẽ ra sao nếu bạn có thể huấn luyện một mô hình AI nghìn tỷ tham số trên 15,5 nghìn tỷ token mà không gặp bất kỳ sự cố nào trong quá trình huấn luyện? Sẽ ra sao nếu bạn có thể tạo ra hàng trăm nghìn ví dụ sử dụng công cụ thực tế mà không cần ghi lại một minh họa nào từ con người? Sẽ ra sao nếu một AI có thể học cách tự đánh giá các phản hồi của chính nó và cải thiện thông qua tự phê bình?
Được phát hành bởi Moonshot AI [1], Kimi K2 đạt được cả ba điều trên — và hoàn toàn là mã nguồn mở. 1) K2 giới thiệu một trình tối ưu hóa mới, kết hợp hiệu quả token của Muon với một cơ chế ổn định tự điều chỉnh gọi là QK-Clip, giúp mô hình ngôn ngữ lớn đạt được không có đột biến mất mát (loss spikes). 2) Thay vì thu thập các minh họa từ con người, đội ngũ K2 đã xây dựng một quy trình mô phỏng hoàn chỉnh để tạo ra hơn 20.000 đặc tả công cụ, phát triển chúng qua các lĩnh vực khác nhau và tạo ra các quỹ đạo sử dụng công cụ đa lượt thực tế. Họ kết hợp môi trường mô phỏng với các sandbox thực thi mã nguồn thực — đạt được cả quy mô và tính xác thực. Và 3) K2 không chỉ học từ các phần thưởng bên ngoài. Nó đã học cách tự đánh giá các phản hồi của mình thông qua cơ chế tự phê bình dựa trên tiêu chí (rubric-based self-critique), mở rộng học tăng cường từ các tác vụ có thể kiểm chứng (mã nguồn vượt qua các bài kiểm tra) sang các lĩnh vực chủ quan (viết sáng tạo, tính hữu ích). Bộ phê bình (critic) của mô hình liên tục cải thiện bằng cách học hỏi từ các tín hiệu khách quan.
2. Những đổi mới chính
2.1) Đổi mới 1: Trình tối ưu hóa MuonClip — Học nhiều hơn từ dữ liệu ít hơn
Hãy tưởng tượng hai sinh viên cùng học một cuốn sách giáo khoa. Sinh viên A (AdamW) đọc kỹ và học tốt — nhưng cần đọc mỗi phần nhiều lần để rút ra tất cả các kiến thức. Sinh viên B (Muon) có kỹ năng ghi chú và tổng hợp tốt hơn, vì vậy có thể hiểu sâu hơn chỉ sau một lần đọc. Với cùng một cuốn sách, Sinh viên B học được nhiều hơn.
Đó chính là hiệu quả token (token efficiency): không phải là đọc ít hơn, mà là học được nhiều hơn từ những gì bạn đọc.
Khi huấn luyện các mạng nơ-ron, chúng ta liên tục cập nhật hàng triệu tham số. Các trình tối ưu hóa truyền thống như Adam hoạt động tốt, nhưng chúng có một điểm kém hiệu quả tinh vi: cập nhật dư thừa.
"Dư thừa" trong mạng nơ-ron có nghĩa là gì?
Khi chúng ta cập nhật các tham số, chúng ta tính toán các gradient (hướng di chuyển). Trong các trình tối ưu hóa truyền thống, các hướng này có thể tương quan với nhau:
Cập nhật tham số (Adam): Trọng số A: +0.500 Trọng số B: +0.495 # Gần như giống hệt A Trọng số C: +0.502 # Cũng gần như giống hệt Trọng số D: -0.003 # Rất nhỏ, hướng khác
Vấn đề: Ba trọng số di chuyển gần như cùng một hướng = dư thừa! Nếu nhiều tham số cập nhật theo các hướng tương quan, bạn đang lãng phí nỗ lực tính toán. Lý tưởng nhất, chúng ta muốn tất cả các cập nhật mang thông tin tối đa, tức là chúng ta muốn Trực giao hóa (Orthogonalization) để làm cho mỗi cập nhật vuông góc với nhau.
Cập nhật tham số (Muon - Đã trực giao hóa): Trọng số A: +0.500 Trọng số B: -0.300 # Hướng vuông góc với A Trọng số C: +0.700 # Một hướng độc lập khác Trọng số D: -0.200 # Một hướng độc nhất khác
Lợi ích: Mỗi cập nhật mang thông tin mới tối đa! Hãy tưởng tượng bạn đang cố gắng vẽ bản đồ một khu rừng tối tăm cùng một đội ngũ các nhà thám hiểm (các tham số của mô hình).
- Cập nhật tương quan (Tiêu chuẩn): Nhóm của bạn nắm tay nhau và cùng đi theo một đường thẳng. Bạn vẽ được con đường đó rất tốt, nhưng phần còn lại của khu rừng vẫn tối tăm. Để vẽ bản đồ toàn bộ khu vực, bạn phải chạy đi chạy lại nhiều lần (nhiều epoch/token hơn).
- Cập nhật trực giao (Muon): Nhóm của bạn tỏa ra. Mỗi người đi theo một hướng hoàn toàn khác nhau. Chỉ trong một bước, nhóm của bạn đã bao phủ được diện tích tối đa có thể của khu rừng.
Theo thuật ngữ đại số tuyến tính, các trình tối ưu hóa tiêu chuẩn như Adam có xu hướng tạo ra các cập nhật “hạng thấp” (low rank). Điều này có nghĩa là ngay cả khi bạn có một ma trận trọng số khổng lồ, trình tối ưu hóa chủ yếu đẩy chúng theo một vài hướng chi phối (các đặc trưng “dễ”). Các đặc trưng tinh vi, phức tạp bị bỏ qua hoặc được học rất chậm. Bằng cách buộc các cập nhật phải trực giao (thông qua lặp Newton-Schulz), Muon đảm bảo cập nhật là “hạng đầy đủ” (Full Rank). Vui lòng tham khảo tại đây để biết chi tiết triển khai.
Hiệu quả token thực sự có nghĩa là gì:
Huấn luyện AI truyền thống sử dụng trình tối ưu hóa AdamW. Nó hoạt động tốt, nhưng đây là hạn chế chính: nếu bạn huấn luyện hai mô hình (một với AdamW, một với Muon) trên cùng 15 nghìn tỷ token, Muon sẽ đạt được hiệu suất tốt hơn.
Hãy nghĩ theo cách này:
- AdamW ở 15 nghìn tỷ token → Mức hiệu suất X
- Muon ở 15 nghìn tỷ token → Mức hiệu suất X + Δ
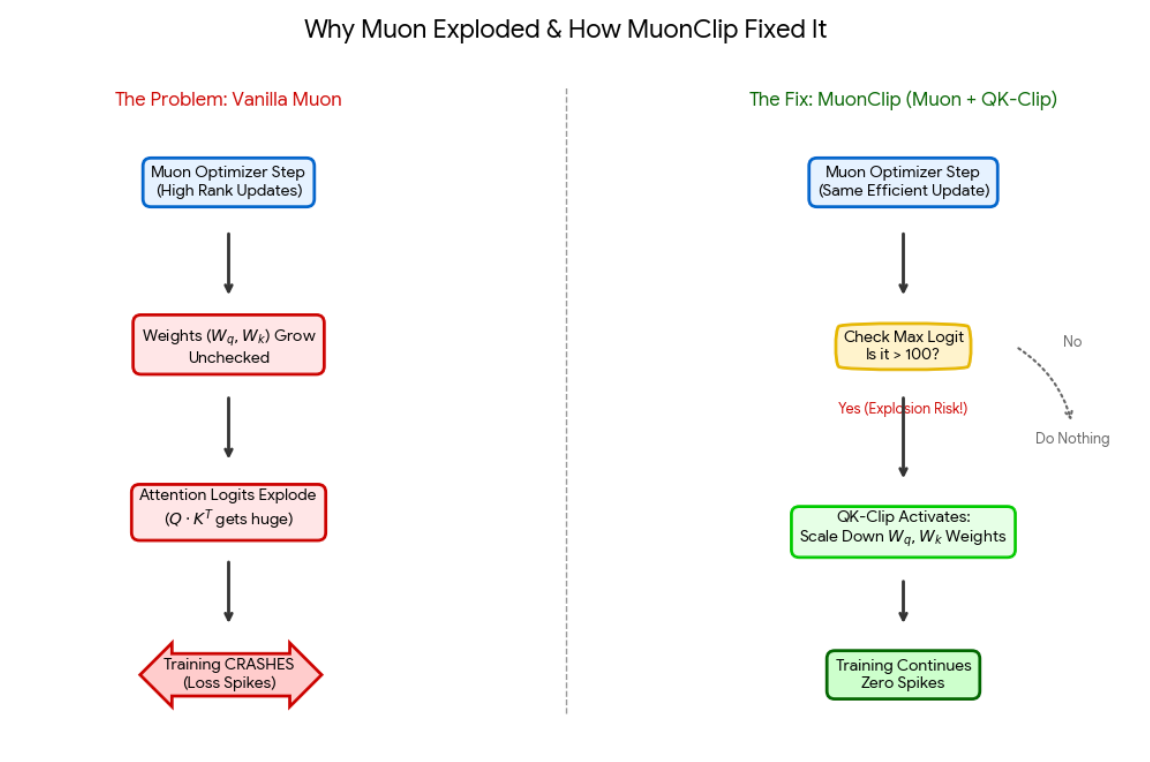
Nhưng có một vấn đề: Muon gặp các vấn đề nghiêm trọng về độ ổn định ở quy mô lớn. Trong quá trình huấn luyện, “logit của attention” có thể tăng vọt — hãy tưởng tượng những con số đáng lẽ chỉ nên ở khoảng 10–20 đột nhiên nhảy lên 1000+. Khi điều này xảy ra, quá trình huấn luyện sẽ bị sập.
Tác giả đã đề xuất MuonClip, kết hợp hiệu quả của Muon với một cơ chế an toàn gọi là QK-Clip để ngăn chặn những vụ nổ đó.
2.2) Đổi mới 2: Làm chủ việc sử dụng công cụ thông qua thực hành tổng hợp
Làm thế nào các phi công học cách xử lý các tình huống khẩn cấp mà không làm rơi máy bay thật? Bằng các trình mô phỏng bay. Họ thực hành hàng ngàn kịch bản — hỏng động cơ, thời tiết xấu, trục trặc hệ thống — trong một môi trường mô phỏng an toàn trước khi chạm vào máy bay thật.
K2 cũng làm điều tương tự cho việc sử dụng công cụ. Họ đã xây dựng một "trình mô phỏng" khổng lồ, nơi mô hình thực hành sử dụng hơn 20.000 công cụ phần mềm khác nhau hàng triệu lần trước khi sử dụng các công cụ thật.
Giải pháp ba giai đoạn:
Giai đoạn 1: Tạo ra hơn 20.000 đặc tả công cụ
- Bắt đầu với các danh mục cấp cao (Tài chính, Y tế, Robot, Game)
- Phát triển các ứng dụng cụ thể trong mỗi danh mục (Giao dịch chứng khoán, Hồ sơ bệnh nhân, Điều khiển drone, AI trong game)
- Tạo ra các công cụ chuyên biệt cho từng ứng dụng
Kết quả là họ đã có được sự đa dạng đáng kinh ngạc — các công cụ cho giao dịch tiền điện tử, điều khiển nhà thông minh, tuân thủ pháp lý, giám sát nông nghiệp và hàng trăm lĩnh vực khác.
Giai đoạn 2: Tạo ra các Agent và tác vụ
Đối với mỗi bộ công cụ, họ đã tạo ra [xem phụ lục 1 để biết đặc tả]:
- Agent: Các prompt hệ thống khác nhau với các kết hợp công cụ khác nhau
- Tác vụ: Các vấn đề từ đơn giản (“Lấy thời tiết cho Bắc Kinh”) đến phức tạp (“Phân tích các mẫu giao dịch và tái cân bằng danh mục đầu tư dựa trên các chỉ số rủi ro”)
- Tiêu chí thành công: Các tiêu chí rõ ràng để xác định việc hoàn thành thành công
Giai đoạn 3: Tạo ra các quỹ đạo huấn luyện
Đây là phần thông minh. Họ đã xây dựng một hệ thống đa agent:
- Agent Lập kế hoạch: Phân rã một tác vụ phức tạp thành các bước nhỏ hơn.
- Agent Thực thi: Chọn công cụ phù hợp nhất cho mỗi bước và thực thi nó.
- Agent Phản hồi: Phân tích kết quả, xác định lỗi và đề xuất các bước tiếp theo.
- Agent Tóm tắt: Tổng hợp các kết quả thành một câu trả lời cuối cùng.
Điều này không chỉ giúp mở rộng quy mô bộ dữ liệu mà còn cung cấp sự đa dạng bằng cách bao quát nhiều kịch bản!
3. Kiến trúc & Kỹ thuật xuất sắc
3.1) Cấu hình MoE: 384 chuyên gia với độ thưa 48×
Hãy tưởng tượng bạn đang xây một ngôi nhà. Bạn không cần mọi người làm mọi việc:
- Khi đổ móng → kích hoạt: kỹ sư kết cấu, chuyên gia bê tông, nhân viên khảo sát
- Khi làm điện → kích hoạt: thợ điện, thanh tra an toàn, chuyên gia tuân thủ quy định
- Khi thiết kế nội thất → kích hoạt: nhà thiết kế nội thất, thợ sơn, thợ mộc
Bạn có hàng tá chuyên gia sẵn sàng, nhưng chỉ những người có liên quan mới làm việc trên mỗi tác vụ. Điều này hiệu quả hơn là có một nhóm nhỏ "thầu khoán tổng hợp" cố gắng làm mọi thứ.
Cách K2 thực hiện:
K2 có 384 mạng nơ-ron chuyên gia (mỗi mạng về cơ bản là một mạng nơ-ron nhỏ, giỏi về các mẫu nhất định).
Đối với mỗi từ/token mà nó xử lý:
- Một "bộ định tuyến" (router) sẽ xem xét token.
- Nó quyết định: "À, token này liên quan đến phân tích cú pháp Python và logic toán học."
- Nó kích hoạt 8 chuyên gia phù hợp nhất (ví dụ: Chuyên gia Python, Chuyên gia Đại số, Chuyên gia Logic).
- Chỉ 8 chuyên gia này thực hiện tính toán. 376 chuyên gia còn lại không hoạt động.
- Kết quả của họ được kết hợp lại.
3.2) Diễn giải lại dữ liệu để tăng tính hữu dụng của token
Hầu hết việc huấn luyện mô hình ngôn ngữ đều lặp lại cùng một dữ liệu nhiều lần (epoch). Lần lặp đầu tiên học nội dung, nhưng các lần lặp sau cho thấy lợi nhuận giảm dần.
Cách tiếp cận truyền thống:
- Epoch 1: “Thủ đô của Pháp là Paris” (học sự thật)
- Epoch 2: “Thủ đô của Pháp là Paris” (củng cố)
- Epoch 3: “Thủ đô của Pháp là Paris” (học thêm rất ít)
Cách của K2: Diễn giải lại thay vì lặp lại
Thay vì hiển thị chính xác cùng một văn bản nhiều lần, hãy diễn giải lại nội dung:
- Phiên bản 1: “Thủ đô của Pháp là Paris”
- Phiên bản 2: “Paris đóng vai trò là thành phố thủ đô của Pháp”
- Phiên bản 3: “Trung tâm chính phủ của Pháp được đặt tại Paris”
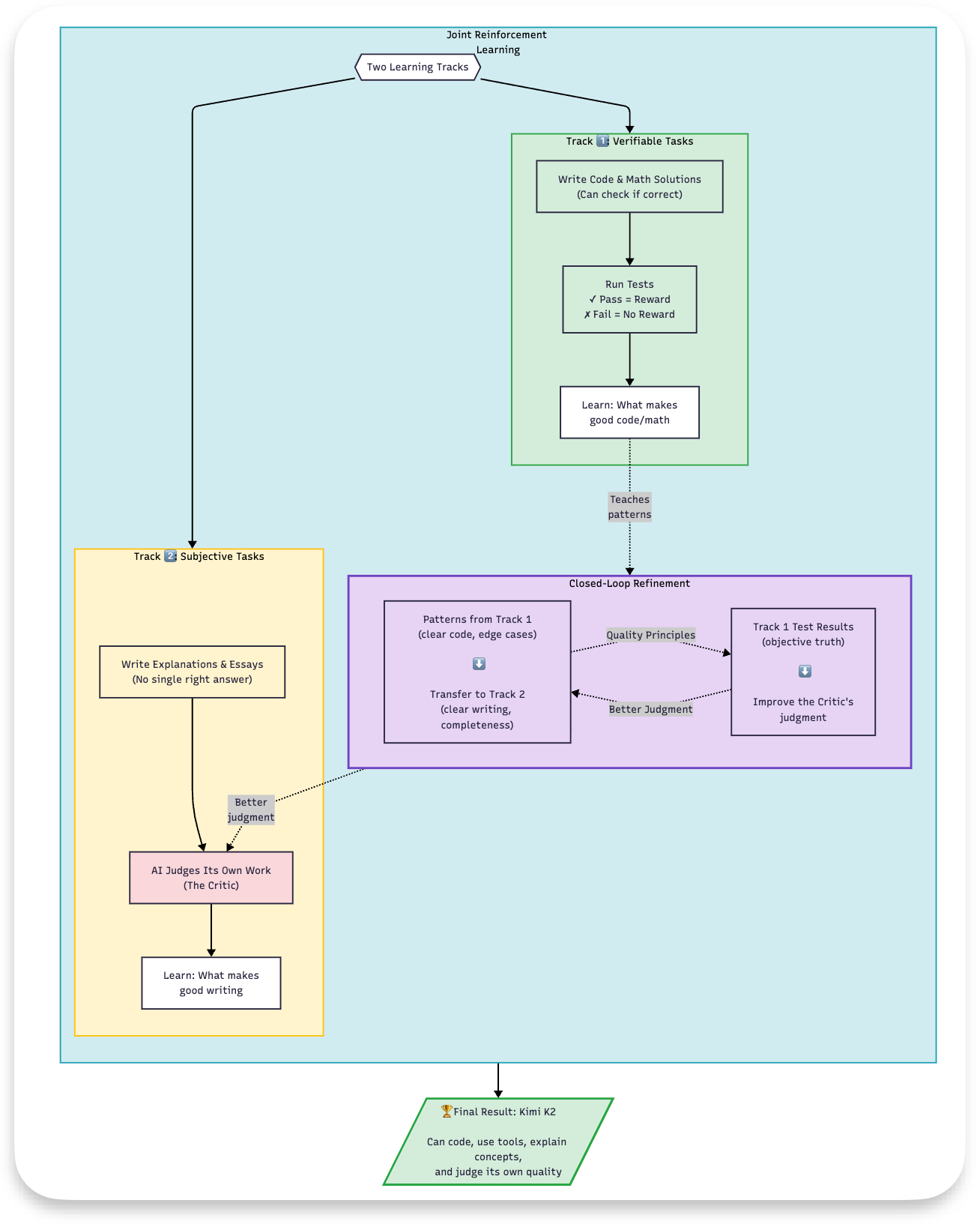
3.3) Huấn luyện RL kết hợp: RLVR + Tự phê bình
Dưới đây là luồng cấp cao cho việc học tăng cường kết hợp (vui lòng xem phụ lục 2 để biết quy trình huấn luyện hoàn chỉnh):
Giai đoạn 1: RLVR (Học tăng cường với phần thưởng có thể kiểm chứng)
Hãy tưởng tượng học cách ném phạt trong bóng rổ:
- Học có giám sát: Xem video về những cú ném hoàn hảo, ghi nhớ kỹ thuật
- Học tăng cường: Thực sự ném 100 lần, nhận phản hồi về những lần ném vào rổ
RL học thông qua thực hành, không chỉ quan sát. Hệ thống của K2 có hai vai trò mà cùng một mô hình đảm nhận:
- Bộ tạo (Generator): Tạo ra nhiều giải pháp cho một vấn đề.
- Bộ phê bình (Critic): Đánh giá chất lượng của các giải pháp đó.
Cách hoạt động đối với mã nguồn:
Vấn đề: "Viết một hàm để tìm các số nguyên tố lên đến N" Mô hình tạo ra K=64 giải pháp khác nhau (khám phá các cách tiếp cận khác nhau) Mỗi giải pháp được thực thi trong một sandbox với các bài kiểm tra đơn vị (unit test) Phần thưởng được gán: Giải pháp A: 15/15 bài kiểm tra đạt → Phần thưởng = 1.0 Giải pháp B: 12/15 bài kiểm tra đạt → Phần thưởng = 0.8 Giải pháp C: 0/15 bài kiểm tra đạt → Phần thưởng = 0.0 Mô hình học: “Các cách tiếp cận tương tự A và B hoạt động tốt. Đừng làm như C.” Ở đây, bộ tạo đưa ra nhiều giải pháp mà bộ phê bình đánh giá bằng cách cung cấp một “điểm dự đoán”. Tiếp theo, chúng ta so sánh điểm này với sự thật ngầm định (groundtruth), tức là bằng cách thực thi mã nguồn.
Hàm mất mát — Phân tích trực quan:
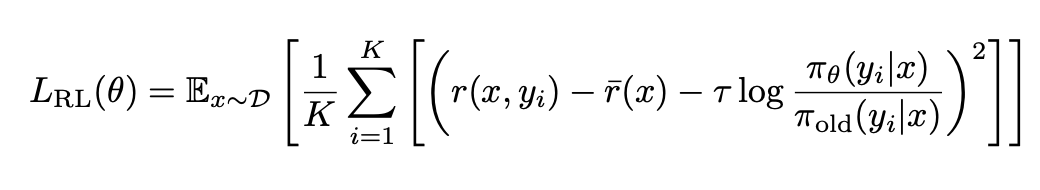
K2 sử dụng một mục tiêu RL chuyên biệt. Đây là chức năng của từng phần:
**(Phần ngoài cùng bên trái) Lợi thế (Advantage) = r(x,y_i) — r̄(x) : **Nó tính toán sự khác biệt giữa phần thưởng cho giải pháp (i) so với phần thưởng trung bình của tất cả K giải pháp. Ví dụ: Nếu giải pháp nhận được phần thưởng 0.8 và trung bình là 0.4 thì Lợi thế = +0.4 (tốt hơn nhiều so với thông thường!), trong khi nếu giải pháp nhận được phần thưởng 0.1 và trung bình là 0.4 thì Lợi thế = -0.3 (tệ hơn nhiều).
**(Phần ngoài cùng bên phải) Thành phần chính quy hóa KL = τ log(π_θ(y_i|x)/π_old(y_i|x)): **Nó đo lường mức độ cập nhật mới đã thay đổi mô hình. Nó giống như thêm một hình phạt nhỏ để đảm bảo chúng ta không thay đổi kết quả quá nhanh và đảm bảo sự ổn định trong quá trình huấn luyện.
Về mặt trực quan, hãy tăng xác suất của các giải pháp có lợi thế dương (tốt hơn mức trung bình), giảm xác suất của các giải pháp có lợi thế âm (tệ hơn mức trung bình), nhưng đừng thay đổi quá nhanh (thành phần τ × KL_penalty ngăn chặn sự mất ổn định).
Giai đoạn 2: Tự phê bình cho các tác vụ chủ quan
Đối với các tác vụ sáng tạo hoặc có kết thúc mở (viết, giải thích, trò chuyện), không có một "câu trả lời đúng" duy nhất. Vì vậy, K2 học cách tự đánh giá bằng cách sử dụng các tiêu chí. Ví dụ: “Giải thích vướng víu lượng tử cho một đứa trẻ 10 tuổi”.
Bước 1: Tạo nhiều phản hồi
Câu hỏi: "Giải thích vướng víu lượng tử cho một đứa trẻ 10 tuổi" Mô hình tạo ra K=8 giải thích khác nhau Mỗi giải thích có một cách tiếp cận khác nhau (dựa trên phép loại suy, dựa trên câu chuyện, từng bước, v.v.)
Bước 2: Mô hình tự đánh giá các phản hồi của mình Mô hình đóng vai trò là nhà phê bình của chính nó bằng cách sử dụng các tiêu chí: Tiêu chí cốt lõi:
- Rõ ràng: Ngôn ngữ phù hợp với lứa tuổi? Dễ theo dõi?
- Chính xác: Khoa học chính xác? Không có tuyên bố gây hiểu lầm?
- Hấp dẫn: Một đứa trẻ có thấy điều này thú vị không?
- Đầy đủ: Trả lời đầy đủ câu hỏi?
Đối với mỗi phản hồi, bộ phê bình chấm điểm từ 1-10 cho mỗi tiêu chí. Dựa trên tiêu chí, chúng ta sẽ sử dụng điểm dự đoán của bộ phê bình và cung cấp lại cho bộ tạo. Nếu bộ phê bình đã học được khả năng phán đoán tốt từ các tác vụ có thể kiểm chứng, thì điểm số của nó cho các tác vụ chủ quan là đáng tin cậy. Tóm lại, bộ phê bình về cơ bản chuyển giao kiến thức đã học của mình cho các tác vụ này.
4. Kết luận
Kimi K2 chứng minh rằng sự đổi mới về thuật toán — cụ thể là trình tối ưu hóa MuonClip ổn định và một quy trình sử dụng công cụ tổng hợp quy mô lớn — có thể mở khóa các khả năng agent tiên tiến trong các mô hình mã nguồn mở mà không cần dựa vào dữ liệu khan hiếm từ con người. Bằng cách huấn luyện thành công một mô hình MoE 1 nghìn tỷ tham số mà không có đột biến mất mát, đội ngũ đã chứng minh rằng hiệu quả token và dữ liệu tổng hợp có thể kiểm chứng là những động lực chính cho việc mở rộng quy mô thế hệ tiếp theo.
Để biết thêm thông tin về mã nguồn hướng dẫn cơ bản, vui lòng tham khảo tại đây — https://github.com/mandeep0405/kimi
Tài liệu tham khảo
(Phần này không có nội dung trong bài gốc)
Phụ lục
1) Typescript thay cho JSON
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for a location and date",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Beijing, China"
},
"date": {
"type": "string",
"description": "Date to query, format YYYY-MM-DD"
}
},
"required": ["location"]
}
}
}
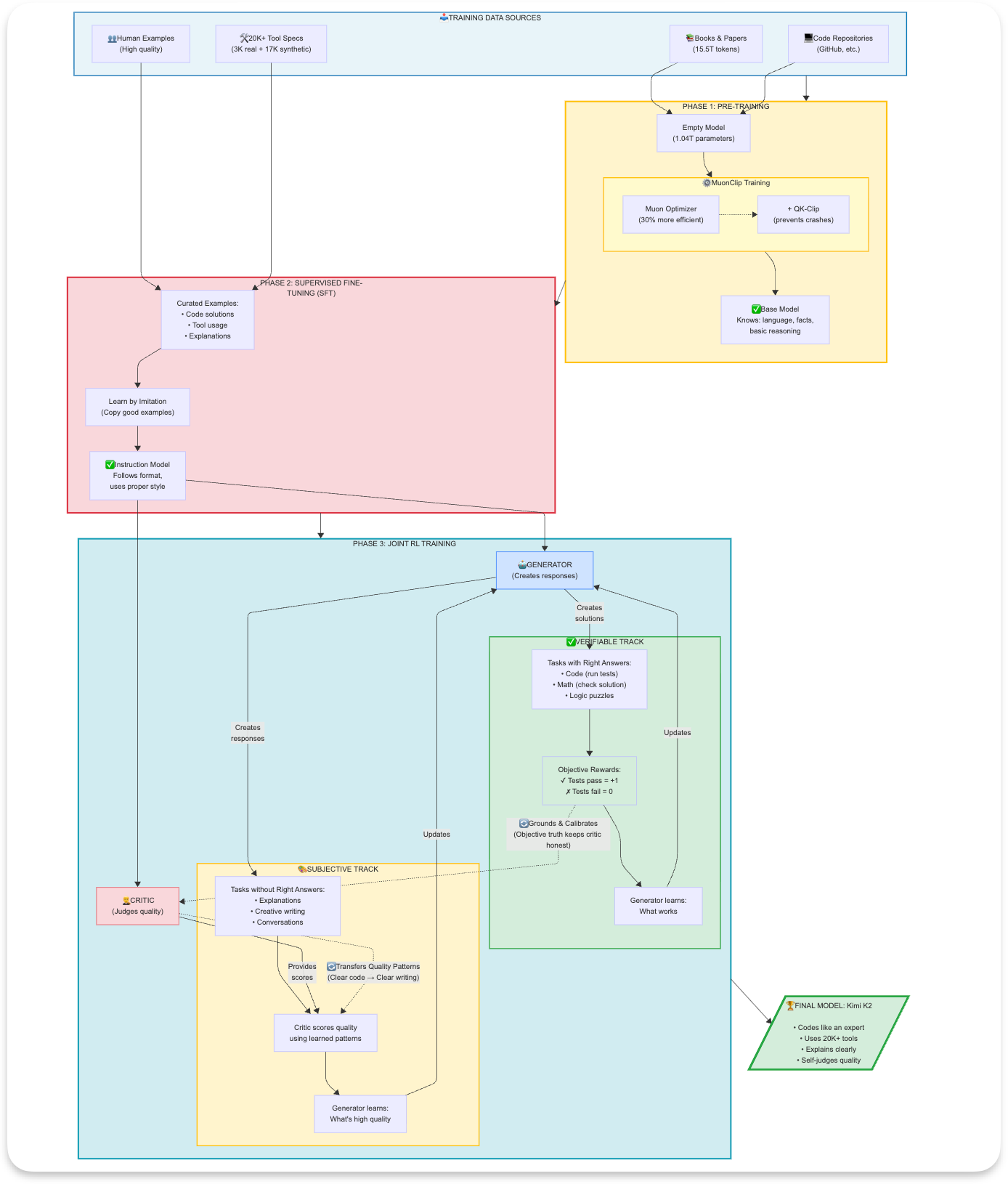
2) Thiết kế đầu cuối
Theo dõi trên X