Xây dựng một pipeline RAG có tư duy sâu và khả năng tự chủ để giải quyết các truy vấn phức tạp

Một hệ thống RAG thường thất bại không phải vì LLM thiếu thông minh, mà vì kiến trúc của nó quá đơn giản. Nó cố gắng xử lý một vấn đề có tính chu kỳ, đa bước bằng một phương pháp tuyến tính, một lần duy nhất.
Nhiều truy vấn phức tạp đòi hỏi suy luận, phản tư, và quyết định thông minh về thời điểm hành động, giống như cách chúng ta truy xuất thông tin khi đối mặt với một câu hỏi. Đó là lúc các hành động do agent điều khiển trong pipeline RAG phát huy tác dụng. Hãy cùng xem một pipeline RAG có tư duy sâu điển hình trông như thế nào...
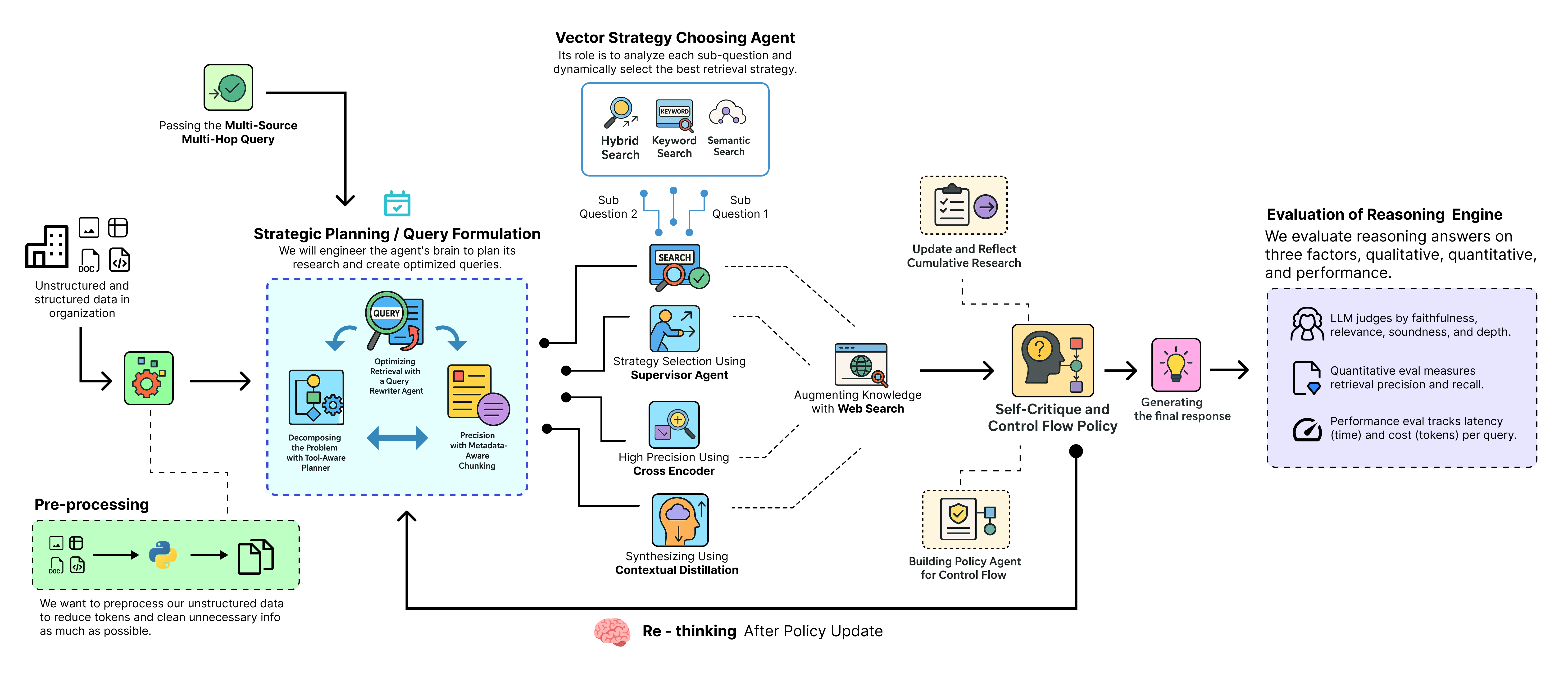 Pipeline RAG tư duy sâu (Tạo bởi Fareed Khan)
Pipeline RAG tư duy sâu (Tạo bởi Fareed Khan)
Trong blog này, chúng ta sẽ triển khai toàn bộ pipeline RAG tư duy sâu và so sánh nó với một pipeline RAG cơ bản để chứng minh cách nó giải quyết các truy vấn đa bước phức tạp.
Toàn bộ mã nguồn và lý thuyết đều có trong Kho lưu trữ GitHub của tôi:
GitHub - FareedKhan-dev/deep-thinking-rag: A Deep Thinking RAG Pipeline to Solve Complex Queries
Một pipeline RAG tư duy sâu để giải quyết các truy vấn phức tạp - GitHub - FareedKhan-dev/deep-thinking-rag: A Deep Thinking RAG…
github.com
Mục lục
- Thiết lập môi trường
- Tìm nguồn cơ sở tri thức
- Hiểu truy vấn đa nguồn, đa bước của chúng ta
- Xây dựng một pipeline RAG nông sẽ thất bại
- Định nghĩa trạng thái RAG cho hệ thống agent trung tâm
- Lập kế hoạch chiến lược và xây dựng truy vấn ∘ Phân rã vấn đề với planner nhận biết công cụ ∘ Tối ưu hóa truy xuất với agent viết lại truy vấn ∘ Độ chính xác với việc phân mảnh nhận biết metadata
- Tạo phễu truy xuất đa giai đoạn ∘ Tự động chọn chiến lược bằng supervisor ∘ Truy xuất rộng với tìm kiếm hybrid, từ khóa và ngữ nghĩa ∘ Độ chính xác cao bằng cách sử dụng cross-encoder reranker ∘ Tổng hợp bằng cách chắt lọc theo ngữ cảnh
- Tăng cường tri thức bằng tìm kiếm trên web
- Tự phê bình và chính sách luồng điều khiển ∘ Cập nhật và phản tư lịch sử nghiên cứu tích lũy ∘ Xây dựng policy agent cho luồng điều khiển
- Định nghĩa các node của đồ thị
- Định nghĩa các cạnh điều kiện
- Kết nối cỗ máy RAG tư duy sâu
- Biên dịch và trực quan hóa quy trình lặp
- Chạy pipeline tư duy sâu
- Phân tích câu trả lời cuối cùng, chất lượng cao
- So sánh song song
- Khung đánh giá và phân tích kết quả
- Tóm tắt toàn bộ pipeline của chúng ta
- Các chính sách đã học với quy trình quyết định Markov (MDP)
Thiết lập môi trường
Trước khi bắt đầu viết mã cho pipeline Deep RAG, chúng ta cần bắt đầu với một nền tảng vững chắc vì một hệ thống AI cấp sản xuất không chỉ là về thuật toán cuối cùng, mà còn là về những lựa chọn có chủ ý mà chúng ta thực hiện trong quá trình thiết lập.
Mỗi bước chúng ta sắp triển khai đều quan trọng trong việc xác định mức độ hiệu quả và đáng tin cậy của hệ thống cuối cùng.
Khi chúng ta bắt đầu phát triển một pipeline và thực hiện thử nghiệm và sửa lỗi với nó, tốt hơn là nên định nghĩa cấu hình của chúng ta ở định dạng từ điển đơn giản vì sau này, khi pipeline trở nên phức tạp, chúng ta có thể chỉ cần tham khảo lại từ điển này để thay đổi cấu hình và xem tác động của nó đối với hiệu suất tổng thể.
# Từ điển cấu hình trung tâm để quản lý tất cả các tham số hệ thống
config = {
"data_dir": "./data", # Thư mục để lưu trữ dữ liệu thô và đã làm sạch
"vector_store_dir": "./vector_store", # Thư mục để duy trì vector store của chúng ta
"llm_provider": "openai", # Nhà cung cấp LLM chúng ta đang sử dụng
"reasoning_llm": "gpt-4o", # Mô hình mạnh mẽ để lập kế hoạch và tổng hợp
"fast_llm": "gpt-4o-mini", # Một mô hình nhanh hơn, rẻ hơn cho các tác vụ đơn giản hơn như RAG cơ bản
"embedding_model": "text-embedding-3-small", # Mô hình để tạo embedding cho tài liệu
"reranker_model": "cross-encoder/ms-marco-MiniLM-L-6-v2", # Mô hình để tái xếp hạng chính xác
"max_reasoning_iterations": 7, # Một biện pháp bảo vệ để ngăn agent rơi vào vòng lặp vô hạn
"top_k_retrieval": 10, # Số lượng tài liệu cho việc truy xuất rộng ban đầu
"top_n_rerank": 3, # Số lượng tài liệu giữ lại sau khi tái xếp hạng chính xác
}
Các khóa này khá dễ hiểu nhưng có ba khóa đáng nói:
llm_provider: Đây là nhà cung cấp LLM chúng ta đang sử dụng, trong trường hợp này là OpenAI. Tôi đang sử dụng OpenAI vì chúng ta có thể dễ dàng hoán đổi các mô hình và nhà cung cấp trong LangChain, nhưng bạn có thể chọn bất kỳ nhà cung cấp nào phù hợp với nhu cầu của mình như Ollama.reasoning_llm: Đây phải là mô hình mạnh nhất trong toàn bộ thiết lập của chúng ta vì nó sẽ được sử dụng để lập kế hoạch và tổng hợp.fast_llm: Đây nên là một mô hình nhanh hơn và rẻ hơn vì nó sẽ được sử dụng cho các tác vụ đơn giản hơn như RAG cơ bản.
Bây giờ chúng ta cần nhập các thư viện cần thiết mà chúng ta sẽ sử dụng trong suốt pipeline của mình cùng với việc đặt các khóa API làm biến môi trường để tránh để lộ chúng trong các khối mã.
import os # Để tương tác với hệ điều hành (ví dụ: quản lý biến môi trường)
import re # Cho các hoạt động biểu thức chính quy, hữu ích cho việc làm sạch văn bản
import json # Để làm việc với dữ liệu JSON
from getpass import getpass # Để nhắc người dùng nhập liệu an toàn như khóa API mà không hiển thị trên màn hình
from pprint import pprint # Để in đẹp các đối tượng Python, làm cho chúng dễ đọc hơn
import uuid # Để tạo các định danh duy nhất
from typing import List, Dict, TypedDict, Literal, Optional # Để gợi ý kiểu nhằm tạo mã sạch, dễ đọc và dễ bảo trì
# Hàm trợ giúp để đặt biến môi trường một cách an toàn nếu chúng chưa tồn tại
def _set_env(var: str):
# Kiểm tra xem biến môi trường đã được đặt chưa
if not os.environ.get(var):
# Nếu chưa, nhắc người dùng nhập nó một cách an toàn
os.environ[var] = getpass(f"Nhập {var} của bạn: ")
# Đặt các khóa API cho các dịch vụ chúng ta sẽ sử dụng
_set_env("OPENAI_API_KEY") # Để truy cập các mô hình OpenAI (GPT-4o, embeddings)
_set_env("LANGSMITH_API_KEY") # Để theo dõi và gỡ lỗi với LangSmith
_set_env("TAVILY_API_KEY") # Cho công cụ tìm kiếm web
# Bật theo dõi LangSmith để nhận nhật ký chi tiết và trực quan hóa việc thực thi của agent
os.environ["LANGSMITH_TRACING"] = "true"
# Định nghĩa một tên dự án trong LangSmith để tổ chức các lần chạy của chúng ta
os.environ["LANGSMITH_PROJECT"] = "Advanced-Deep-Thinking-RAG"
Chúng tôi cũng đang bật LangSmith để theo dõi. Khi bạn làm việc với một hệ thống agentic có quy trình làm việc phức tạp, theo chu kỳ, việc theo dõi không chỉ là một thứ hay ho mà nó còn rất quan trọng. Nó giúp bạn hình dung những gì đang diễn ra và giúp việc gỡ lỗi quá trình suy nghĩ của agent trở nên dễ dàng hơn nhiều.
Tìm nguồn cơ sở tri thức
Một hệ thống RAG cấp sản xuất đòi hỏi một cơ sở tri thức vừa phức tạp vừa đòi hỏi cao để thực sự chứng minh được hiệu quả của nó. Vì mục đích này, chúng ta sẽ sử dụng báo cáo 10-K năm 2023 của NVIDIA (NVIDIA’s 2023 10-K filing), một tài liệu toàn diện dài hơn một trăm trang chi tiết về hoạt động kinh doanh, hiệu suất tài chính và các yếu tố rủi ro đã được công bố của công ty.
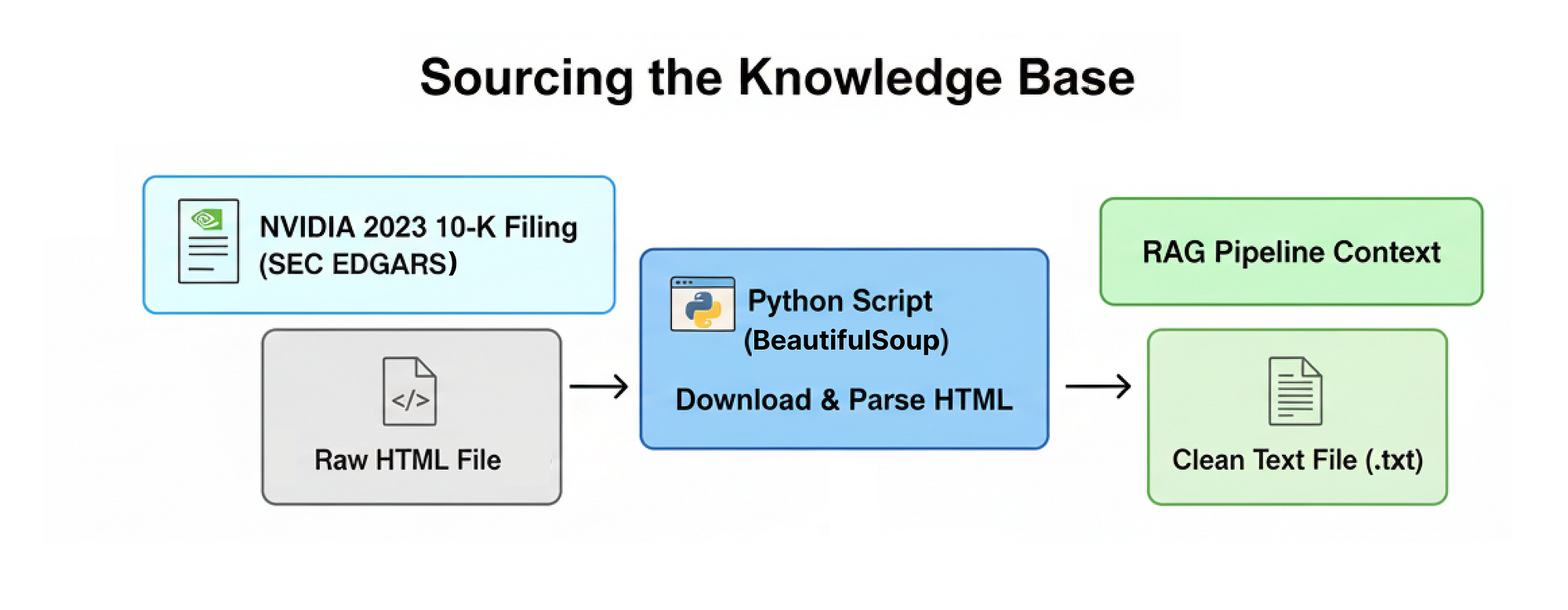 Tìm nguồn cơ sở tri thức (Tạo bởi Fareed Khan)
Tìm nguồn cơ sở tri thức (Tạo bởi Fareed Khan)
Đầu tiên, chúng ta sẽ triển khai một hàm tùy chỉnh để tải xuống báo cáo 10-K một cách tự động trực tiếp từ cơ sở dữ liệu SEC EDGAR, phân tích cú pháp HTML thô và chuyển đổi nó thành định dạng văn bản sạch và có cấu trúc phù hợp để pipeline RAG của chúng ta tiếp nhận. Vậy hãy viết mã cho hàm đó.
import requests # Để thực hiện các yêu cầu HTTP để tải tài liệu
from bs4 import BeautifulSoup # Một thư viện mạnh mẽ để phân tích cú pháp tài liệu HTML và XML
from langchain.docstore.document import Document # Cấu trúc dữ liệu tiêu chuẩn của LangChain cho một đoạn văn bản
def download_and_parse_10k(url, doc_path_raw, doc_path_clean):
# Kiểm tra xem tệp đã làm sạch đã tồn tại chưa để tránh tải lại
if os.path.exists(doc_path_clean):
print(f"Tệp 10-K đã làm sạch đã tồn tại tại: {doc_path_clean}")
return
print(f"Đang tải báo cáo 10-K từ {url}...")
# Đặt tiêu đề User-Agent để giả mạo trình duyệt, vì một số máy chủ chặn script
headers = {'User-Agent': 'Mozilla/5.0'}
# Thực hiện yêu cầu GET đến URL
response = requests.get(url, headers=headers)
# Gây ra lỗi nếu tải xuống thất bại (ví dụ: 404 Not Found)
response.raise_for_status()
# Lưu nội dung HTML thô vào một tệp để kiểm tra
with open(doc_path_raw, 'w', encoding='utf-8') as f:
f.write(response.text)
print(f"Tài liệu thô đã được lưu vào {doc_path_raw}")
# Sử dụng BeautifulSoup để phân tích và làm sạch nội dung HTML
soup = BeautifulSoup(response.content, 'html.parser')
# Trích xuất văn bản từ các thẻ HTML phổ biến, cố gắng bảo toàn cấu trúc đoạn văn
text = ''
for p in soup.find_all(['p', 'div', 'span']):
# Lấy văn bản từ mỗi thẻ, loại bỏ khoảng trắng thừa và thêm dòng mới
text += p.get_text(strip=True) + '\n\n'
# Sử dụng regex để dọn dẹp các dòng mới và khoảng trắng thừa để có văn bản cuối cùng sạch hơn
clean_text = re.sub(r'\n{3,}', '\n\n', text).strip() # Gộp 3+ dòng mới thành 2
clean_text = re.sub(r'\s{2,}', ' ', clean_text).strip() # Gộp 2+ khoảng trắng thành 1
# Lưu văn bản đã làm sạch cuối cùng vào một tệp .txt
with open(doc_path_clean, 'w', encoding='utf-8') as f:
f.write(clean_text)
print(f"Nội dung văn bản đã làm sạch được trích xuất và lưu vào {doc_path_clean}")
Mã này khá dễ hiểu, chúng ta đang sử dụng beautifulsoup4 để phân tích nội dung HTML và trích xuất văn bản. Nó sẽ giúp chúng ta dễ dàng điều hướng cấu trúc HTML và truy xuất thông tin liên quan trong khi bỏ qua bất kỳ yếu tố không cần thiết nào như script hoặc style.
Bây giờ, hãy thực thi điều này và xem nó hoạt động như thế nào.
print("Đang tải xuống và phân tích báo cáo 10-K năm 2023 của NVIDIA...")
# Thực thi hàm tải xuống và phân tích
download_and_parse_10k(url_10k, doc_path_raw, doc_path_clean)
# Mở tệp đã làm sạch và in một mẫu để xác minh kết quả
with open(doc_path_clean, 'r', encoding='utf-8') as f:
print("\n--- Mẫu nội dung từ 10-K đã làm sạch ---")
print(f.read(1000) + "...")
#### ĐẦU RA ####
Đang tải xuống và phân tích báo cáo 10-K năm 2023 của NVIDIA...
Tải xuống thành công báo cáo 10-K từ https://www.sec.gov/Archives/edgar/data/1045810/000104581023000017/nvda-20230129.htm
Tài liệu thô đã được lưu vào ./data/nvda_10k_2023_raw.html
Nội dung văn bản đã làm sạch được trích xuất và lưu vào ./data/nvda_10k_2023_clean.txt
# --- Mẫu nội dung từ 10-K đã làm sạch ---
Item 1. Business.
OVERVIEW
NVIDIA is the pioneer of accelerated computing. We are a full-stack computing company with a platform strategy that brings together hardware, systems, software, algorithms, libraries, and services to create unique value for the markets we serve. Our work in accelerated computing and AI is reshaping the worlds largest industries and profoundly impacting society.
Founded in 1993, we started as a PC graphics chip company, inventing the graphics processing unit, or GPU. The GPU was essential for the growth of the PC gaming market and has since been repurposed to revolutionize computer graphics, high performance computing, or HPC, and AI.
The programmability of our GPUs made them ...
Chúng ta chỉ đơn giản gọi hàm này để lưu trữ tất cả nội dung vào một tệp txt sẽ đóng vai trò là ngữ cảnh cho pipeline RAG của chúng ta.
Khi chúng ta chạy đoạn mã trên, bạn có thể thấy nó bắt đầu tải xuống báo cáo cho chúng ta và chúng ta có thể xem một mẫu nội dung đã tải xuống trông như thế nào.
Hiểu truy vấn đa nguồn, đa bước của chúng ta
Để kiểm tra pipeline đã triển khai và so sánh nó với RAG cơ bản, chúng ta cần sử dụng một truy vấn rất phức tạp bao gồm các khía cạnh khác nhau của tài liệu mà chúng ta đang làm việc.
Truy vấn phức tạp của chúng ta:
"Dựa trên báo cáo 10-K năm 2023 của NVIDIA, hãy xác định các rủi ro chính của họ liên quan đến cạnh tranh. Sau đó, tìm tin tức gần đây (sau ngày nộp báo cáo, từ năm 2024) về chiến lược chip AI của AMD và giải thích chiến lược mới này trực tiếp giải quyết hoặc làm trầm trọng thêm một trong những rủi ro đã nêu của NVIDIA như thế nào."
Hãy phân tích tại sao truy vấn này lại khó đối với một pipeline RAG tiêu chuẩn:
Trong phần tiếp theo, chúng ta sẽ triển khai pipeline RAG cơ bản và thực sự xem RAG đơn giản thất bại như thế nào.
Xây dựng một pipeline RAG nông sẽ thất bại
Bây giờ chúng ta đã cấu hình môi trường và chuẩn bị sẵn cơ sở tri thức đầy thách thức, bước hợp lý tiếp theo của chúng ta là xây dựng một pipeline RAG vanilla tiêu chuẩn. Điều này phục vụ một mục đích quan trọng...
Đầu tiên, bằng cách xây dựng giải pháp đơn giản nhất có thể, chúng ta có thể chạy truy vấn phức tạp của mình trên đó và quan sát chính xác cách thức và lý do nó thất bại.
Đây là những gì chúng ta sẽ làm trong phần này:
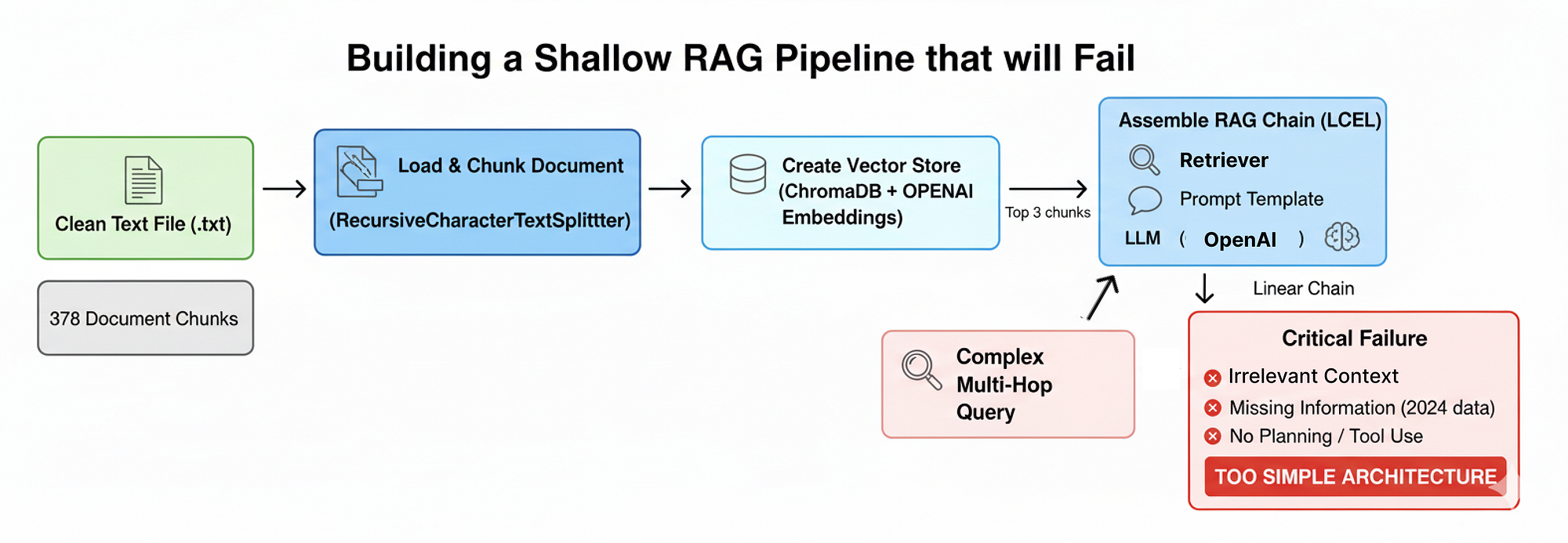 Pipeline RAG nông (Tạo bởi Fareed Khan)
Pipeline RAG nông (Tạo bởi Fareed Khan)
- Tải và phân mảnh tài liệu: Chúng ta sẽ nhập báo cáo 10-K đã làm sạch và chia nó thành các mảnh nhỏ, có kích thước cố định, một cách tiếp cận phổ biến nhưng ngây thơ về mặt ngữ nghĩa.
- Tạo một vector store: Sau đó, chúng ta sẽ nhúng các mảnh này và lập chỉ mục chúng trong một vector store ChromaDB để cho phép tìm kiếm ngữ nghĩa cơ bản.
- Lắp ráp chuỗi RAG: Chúng ta sẽ sử dụng Ngôn ngữ Biểu thức LangChain (LCEL), sẽ kết nối retriever, một mẫu prompt và một LLM thành một pipeline tuyến tính.
- Chứng minh sự thất bại nghiêm trọng: Chúng ta sẽ thực thi truy vấn đa bước, đa nguồn của mình trên hệ thống đơn giản này và phân tích phản hồi không đầy đủ của nó.
Đầu tiên, chúng ta cần tải tài liệu đã làm sạch và chia nhỏ nó. Chúng ta sẽ sử dụng RecursiveCharacterTextSplitter, một công cụ tiêu chuẩn trong hệ sinh thái LangChain.
from langchain_community.document_loaders import TextLoader # Một loader đơn giản cho các tệp .txt
from langchain.text_splitter import RecursiveCharacterTextSplitter # Một bộ chia văn bản tiêu chuẩn
print("Đang tải và phân mảnh tài liệu...")
# Khởi tạo loader với đường dẫn đến tệp 10-K đã làm sạch của chúng ta
loader = TextLoader(doc_path_clean, encoding='utf-8')
# Tải tài liệu vào bộ nhớ
documents = loader.load()
# Khởi tạo bộ chia văn bản với kích thước chunk và độ chồng chéo đã xác định
# chunk_size=1000: Mỗi chunk sẽ dài khoảng 1000 ký tự.
# chunk_overlap=150: Mỗi chunk sẽ chia sẻ 150 ký tự với chunk trước đó để duy trì một số ngữ cảnh.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=150)
# Chia tài liệu đã tải thành các chunk nhỏ hơn, dễ quản lý
doc_chunks = text_splitter.split_documents(documents)
print(f"Tài liệu đã được tải và chia thành {len(doc_chunks)} chunk.")
#### ĐẦU RA ####
Đang tải và phân mảnh tài liệu...
Tài liệu đã được tải và chia thành 378 chunk.
Chúng ta có 378 chunk trên tài liệu chính của mình, bước tiếp theo là làm cho chúng có thể tìm kiếm được. Để làm điều này, chúng ta cần tạo các vector embedding và lưu trữ chúng trong một cơ sở dữ liệu. Chúng ta sẽ sử dụng ChromaDB, một vector store trong bộ nhớ phổ biến, và mô hình OpenAI text-embedding-3-small như đã định nghĩa trong cấu hình của chúng ta.
from langchain_community.vectorstores import Chroma # Vector store chúng ta sẽ sử dụng
from langchain_openai import OpenAIEmbeddings # Hàm để tạo embeddings
print("Đang tạo vector store cơ bản...")
# Khởi tạo hàm embedding sử dụng mô hình được chỉ định trong cấu hình của chúng ta
embedding_function = OpenAIEmbeddings(model=config['embedding_model'])
# Tạo vector store Chroma từ các chunk tài liệu của chúng ta
# Quá trình này lấy mỗi chunk, tạo một embedding cho nó và lập chỉ mục.
baseline_vector_store = Chroma.from_documents(
documents=doc_chunks,
embedding=embedding_function
)
# Tạo một retriever từ vector store
# Retriever là thành phần sẽ thực sự thực hiện tìm kiếm.
# search_kwargs={"k": 3}: Điều này cho retriever biết trả về 3 chunk liên quan nhất cho bất kỳ truy vấn nào.
baseline_retriever = baseline_vector_store.as_retriever(search_kwargs={"k": 3})
print(f"Vector store được tạo với {baseline_vector_store._collection.count()} embedding.")
#### ĐẦU RA ####
Đang tạo vector store cơ bản...
Vector store được tạo với 378 embedding.
Chroma.from_documents tổ chức quá trình này và lưu trữ tất cả các vector trong một chỉ mục có thể tìm kiếm. Bước cuối cùng là lắp ráp chúng thành một chuỗi RAG duy nhất, có thể chạy được bằng Ngôn ngữ Biểu thức LangChain (LCEL).
Chuỗi này sẽ xác định luồng dữ liệu tuyến tính: từ câu hỏi của người dùng đến retriever, sau đó đến prompt và cuối cùng là LLM.
from langchain_core.prompts import ChatPromptTemplate # Để tạo các mẫu prompt
from langchain_openai import ChatOpenAI # Giao diện mô hình trò chuyện OpenAI
from langchain_core.runnable import RunnablePassthrough # Một công cụ để truyền đầu vào qua chuỗi
from langchain_core.output_parsers import StrOutputParser # Để phân tích đầu ra của LLM thành một chuỗi đơn giản
# Mẫu này hướng dẫn LLM cách hành xử.
# {context}: Đây là nơi chúng ta sẽ đưa nội dung từ các tài liệu được truy xuất.
# {question}: Đây là nơi câu hỏi ban đầu của người dùng sẽ được đặt.
template = """Bạn là một nhà phân tích tài chính AI. Hãy trả lời câu hỏi chỉ dựa trên ngữ cảnh sau:
{context}
Câu hỏi: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# Chúng ta sử dụng 'fast_llm' của mình cho tác vụ đơn giản này, như đã định nghĩa trong cấu hình
llm = ChatOpenAI(model=config["fast_llm"], temperature=0)
# Một hàm trợ giúp để định dạng danh sách các tài liệu được truy xuất thành một chuỗi duy nhất
def format_docs(docs):
return "\n\n---\n\n".join(doc.page_content for doc in docs)
# Chuỗi RAG hoàn chỉnh được định nghĩa bằng cú pháp pipe (|) của LCEL
baseline_rag_chain = (
# Bước đầu tiên là một từ điển định nghĩa các đầu vào cho prompt của chúng ta
{"context": baseline_retriever | format_docs, "question": RunnablePassthrough()}
# Ngữ cảnh được tạo bằng cách lấy câu hỏi, truyền nó cho retriever và định dạng kết quả
# Câu hỏi ban đầu được truyền qua không thay đổi
| prompt # Từ điển sau đó được truyền cho mẫu prompt
| llm # Prompt đã định dạng được truyền cho mô hình ngôn ngữ
| StrOutputParser() # Thông điệp đầu ra của LLM được phân tích thành một chuỗi
)
Bạn biết rằng chúng ta định nghĩa một từ điển là bước đầu tiên. Khóa context của nó được điền bởi một chuỗi con, câu hỏi đầu vào đi đến baseline_retriever, và đầu ra của nó (một danh sách các đối tượng Document) được định dạng thành một chuỗi duy nhất bởi format_docs. Khóa question được điền bằng cách chỉ cần truyền đầu vào ban đầu qua bằng RunnablePassthrough.
Hãy chạy pipeline đơn giản này và hiểu nó đang thất bại ở đâu.
from rich.console import Console # Để in đẹp đầu ra với markdown
from rich.markdown import Markdown
# Khởi tạo rich console để định dạng đầu ra tốt hơn
console = Console()
# Truy vấn phức tạp, đa bước, đa nguồn của chúng ta
complex_query_adv = "Dựa trên báo cáo 10-K năm 2023 của NVIDIA, hãy xác định các rủi ro chính của họ liên quan đến cạnh tranh. Sau đó, tìm tin tức gần đây (sau ngày nộp báo cáo, từ năm 2024) về chiến lược chip AI của AMD và giải thích chiến lược mới này trực tiếp giải quyết hoặc làm trầm trọng thêm một trong những rủi ro đã nêu của NVIDIA như thế nào."
print("Đang thực thi truy vấn phức tạp trên chuỗi RAG cơ bản...")
# Gọi chuỗi với truy vấn đầy thách thức của chúng ta
baseline_result = baseline_rag_chain.invoke(complex_query_adv)
console.print("\n--- ĐẦU RA THẤT BẠI CỦA RAG CƠ BẢN ---")
# In kết quả bằng định dạng markdown để dễ đọc
console.print(Markdown(baseline_result))
Khi bạn chạy đoạn mã trên, chúng ta nhận được đầu ra sau.
#### ĐẦU RA ####
Đang thực thi truy vấn phức tạp trên chuỗi RAG cơ bản...
--- ĐẦU RA THẤT BẠI CỦA RAG CƠ BẢN ---
Dựa trên ngữ cảnh được cung cấp, NVIDIA hoạt động trong một ngành công nghiệp bán dẫn cạnh tranh khốc liệt và đối mặt với sự cạnh tranh từ các công ty như AMD. Ngữ cảnh đề cập rằng ngành công nghiệp này được đặc trưng bởi sự thay đổi công nghệ nhanh chóng. Tuy nhiên, các tài liệu được cung cấp không chứa bất kỳ thông tin cụ thể nào về chiến lược chip AI gần đây của AMD từ năm 2024 hoặc cách nó có thể ảnh hưởng đến các rủi ro đã nêu của NVIDIA.
Có ba điều bạn có thể đã nhận thấy trong pipeline RAG thất bại này và đầu ra của nó.
- Ngữ cảnh không liên quan: Retriever lấy các chunk chung về “NVIDIA”, “cạnh tranh” và “AMD” nhưng bỏ lỡ các chi tiết cụ thể về chiến lược của AMD năm 2024.
- Thiếu thông tin: Thất bại chính là dữ liệu năm 2023 không thể bao gồm các sự kiện năm 2024. Hệ thống không nhận ra rằng nó đang thiếu thông tin quan trọng.
- Không lập kế hoạch hoặc sử dụng công cụ: Coi truy vấn phức tạp như một truy vấn đơn giản. Không thể chia nó thành các bước hoặc sử dụng các công cụ như tìm kiếm web để lấp đầy khoảng trống.
Hệ thống đã thất bại không phải vì LLM ngu ngốc mà vì kiến trúc quá đơn giản. Đó là một quy trình tuyến tính, một lần duy nhất cố gắng giải quyết một vấn đề có tính chu kỳ, đa bước.
Bây giờ chúng ta đã hiểu các vấn đề với pipeline RAG cơ bản của mình, chúng ta có thể bắt đầu triển khai phương pháp tư duy sâu và xem nó giải quyết truy vấn phức tạp của chúng ta tốt như thế nào.
Định nghĩa RAG State cho hệ thống agent trung tâm
Để xây dựng agent suy luận của chúng ta, trước tiên chúng ta cần một cách để quản lý trạng thái của nó. Trong chuỗi RAG đơn giản của chúng ta, mỗi bước đều không có trạng thái, nhưng...
một agent thông minh, tuy nhiên, cần một bộ nhớ. Nó cần nhớ câu hỏi ban đầu, kế hoạch nó đã tạo ra và bằng chứng nó đã thu thập được cho đến nay.
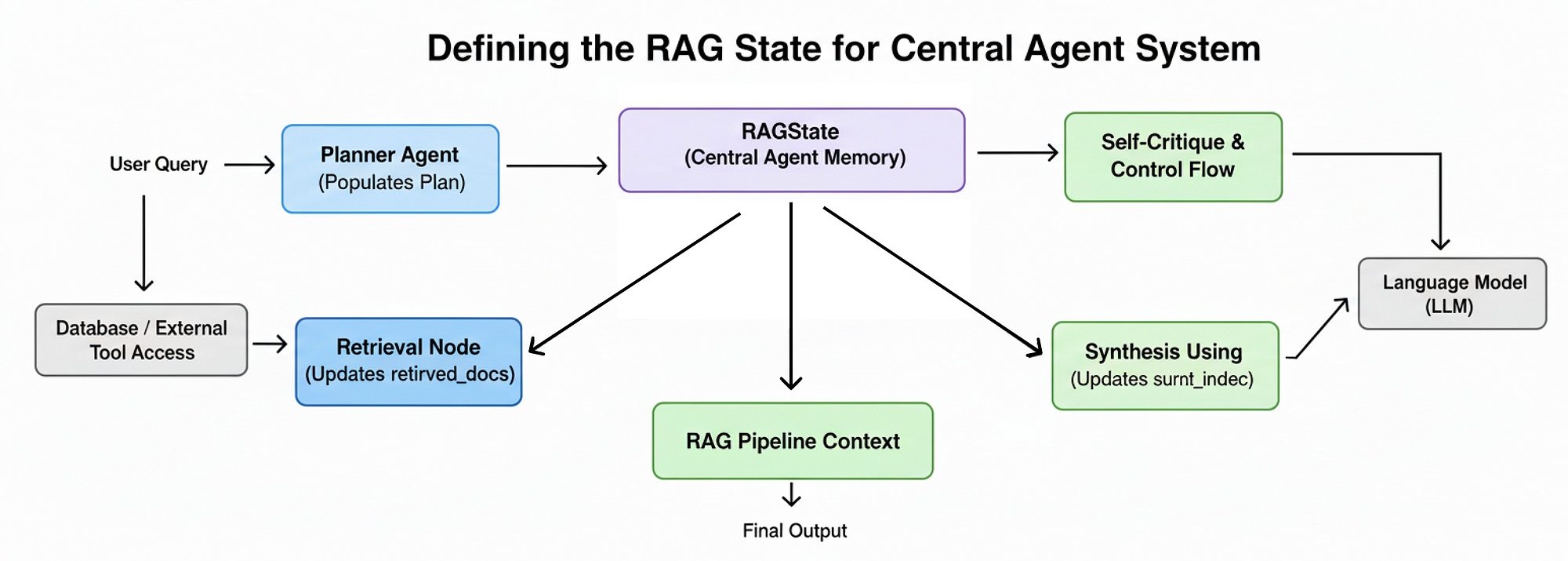 Trạng thái RAG (Tạo bởi Fareed Khan)
Trạng thái RAG (Tạo bởi Fareed Khan)
RAGState sẽ hoạt động như một bộ nhớ trung tâm, được truyền giữa mọi node trong quy trình làm việc LangGraph của chúng ta. Để xây dựng nó, chúng ta sẽ định nghĩa một loạt các lớp dữ liệu có cấu trúc, bắt đầu với khối xây dựng cơ bản nhất: một bước duy nhất trong một kế hoạch nghiên cứu.
Chúng ta muốn định nghĩa đơn vị nguyên tử của kế hoạch của agent. Mỗi Step không chỉ phải chứa một câu hỏi cần được trả lời, mà còn cả lý do đằng sau nó và, quan trọng là, công cụ cụ thể mà agent nên sử dụng. Điều này buộc quá trình lập kế hoạch của agent phải rõ ràng và có cấu trúc.
from langchain_core.documents import Document
from langchain_core.pydantic_v1 import BaseModel, Field
# Mô hình Pydantic cho một bước duy nhất trong kế hoạch suy luận của agent
class Step(BaseModel):
# Một câu hỏi phụ cụ thể, có thể trả lời được cho bước nghiên cứu này
sub_question: str = Field(description="Một câu hỏi cụ thể, có thể trả lời được cho bước này.")
# Lý do của agent về tại sao bước này là cần thiết
justification: str = Field(description="Một lời giải thích ngắn gọn về lý do tại sao bước này cần thiết để trả lời truy vấn chính.")
# Công cụ cụ thể để sử dụng cho bước này: hoặc tìm kiếm tài liệu nội bộ hoặc tìm kiếm web bên ngoài
tool: Literal["search_10k", "search_web"] = Field(description="Công cụ để sử dụng cho bước này.")
# Một danh sách các từ khóa quan trọng để cải thiện độ chính xác của tìm kiếm
keywords: List[str] = Field(description="Một danh sách các từ khóa quan trọng để tìm kiếm các phần tài liệu liên quan.")
# (Tùy chọn) Một phần tài liệu có khả năng để thực hiện tìm kiếm được lọc, có mục tiêu hơn
document_section: Optional[str] = Field(description="Một tiêu đề phần tài liệu có khả năng (ví dụ: 'Item 1A. Risk Factors') để tìm kiếm bên trong. Chỉ dành cho công cụ 'search_10k'.")
Lớp Step của chúng ta, sử dụng Pydantic BaseModel, hoạt động như một hợp đồng nghiêm ngặt cho Planner Agent của chúng ta. Trường tool: Literal[...] buộc LLM phải đưa ra quyết định cụ thể giữa việc sử dụng kiến thức nội bộ của chúng ta (search_10k) hoặc tìm kiếm thông tin bên ngoài (search_web).
Đầu ra có cấu trúc này đáng tin cậy hơn nhiều so với việc cố gắng phân tích một kế hoạch bằng ngôn ngữ tự nhiên.
Bây giờ chúng ta đã định nghĩa một Step duy nhất, chúng ta cần một vùng chứa để giữ toàn bộ chuỗi các bước. Chúng ta sẽ tạo một lớp Plan đơn giản là một danh sách các đối tượng Step. Điều này đại diện cho chiến lược nghiên cứu từ đầu đến cuối hoàn chỉnh của agent.
# Mô hình Pydantic cho kế hoạch tổng thể, là một danh sách các bước riêng lẻ
class Plan(BaseModel):
# Một danh sách các đối tượng Step phác thảo kế hoạch nghiên cứu đầy đủ
steps: List[Step] = Field(description="Một kế hoạch chi tiết, nhiều bước để trả lời truy vấn của người dùng.")
Chúng ta đã viết một lớp Plan sẽ cung cấp cấu trúc cho toàn bộ quá trình nghiên cứu. Khi chúng ta gọi Planner Agent của mình, chúng ta sẽ yêu cầu nó trả về một đối tượng JSON tuân thủ lược đồ này. Điều này đảm bảo rằng chiến lược của agent rõ ràng, tuần tự và có thể đọc được bằng máy trước khi bất kỳ hành động truy xuất nào được thực hiện.
Tiếp theo, khi agent của chúng ta thực hiện kế hoạch của mình, nó cần một cách để ghi nhớ những gì nó đã học được. Chúng ta sẽ định nghĩa một từ điển PastStep để lưu trữ kết quả của mỗi bước đã hoàn thành. Điều này sẽ hình thành lịch sử nghiên cứu hoặc sổ tay phòng thí nghiệm của agent.
# Một TypedDict để lưu trữ kết quả của một bước đã hoàn thành trong lịch sử nghiên cứu của chúng ta
class PastStep(TypedDict):
step_index: int # Chỉ số của bước đã hoàn thành (ví dụ: 1, 2, 3)
sub_question: str # Câu hỏi phụ đã được giải quyết trong bước này
retrieved_docs: List[Document] # Các tài liệu chính xác được truy xuất và tái xếp hạng cho bước này
summary: str # Tóm tắt một câu của agent về những phát hiện từ bước này
Cấu trúc PastStep này rất quan trọng cho vòng lặp tự phê bình của agent. Sau mỗi bước, chúng ta sẽ điền vào một trong những từ điển này và thêm nó vào trạng thái của chúng ta. Agent sau đó sẽ có thể xem lại danh sách tóm tắt ngày càng tăng này để hiểu những gì nó biết và quyết định xem nó có đủ thông tin để hoàn thành nhiệm vụ của mình hay không.
Cuối cùng, chúng ta sẽ tập hợp tất cả các phần này lại thành từ điển RAGState chính. Đây là đối tượng trung tâm sẽ chảy qua toàn bộ đồ thị của chúng ta, chứa truy vấn ban đầu, kế hoạch đầy đủ, lịch sử các bước đã qua và tất cả dữ liệu trung gian cho bước hiện tại đang được thực thi.
# Từ điển trạng thái chính sẽ được truyền giữa tất cả các node trong agent LangGraph của chúng ta
class RAGState(TypedDict):
original_question: str # Truy vấn phức tạp ban đầu từ người dùng bắt đầu quá trình
plan: Plan # Kế hoạch nhiều bước được tạo bởi Planner Agent
past_steps: List[PastStep] # Lịch sử tích lũy của các bước nghiên cứu đã hoàn thành và kết quả của chúng
current_step_index: int # Chỉ số của bước hiện tại trong kế hoạch đang được thực thi
retrieved_docs: List[Document] # Các tài liệu được truy xuất trong bước hiện tại (kết quả của truy xuất rộng)
reranked_docs: List[Document] # Các tài liệu sau khi tái xếp hạng chính xác trong bước hiện tại
synthesized_context: str # Ngữ cảnh ngắn gọn, chắt lọc được tạo từ các tài liệu đã tái xếp hạng
final_answer: str # Câu trả lời cuối cùng, được tổng hợp cho câu hỏi ban đầu của người dùng
RAGState TypedDict này là bộ não hoàn chỉnh của agent của chúng ta. Mọi node trong đồ thị của chúng ta sẽ nhận từ điển này làm đầu vào và trả về một phiên bản cập nhật của nó làm đầu ra.
Ví dụ, plan_node sẽ điền vào trường plan, retrieval_node sẽ điền vào trường retrieved_docs, và cứ thế. Trạng thái chung, bền vững này là thứ cho phép suy luận lặp đi lặp lại, phức tạp mà chuỗi RAG đơn giản của chúng ta thiếu.
Với bản thiết kế cho bộ nhớ của agent đã được định nghĩa, chúng ta đã sẵn sàng để xây dựng thành phần nhận thức đầu tiên của hệ thống: Planner Agent sẽ điền vào trạng thái này.
Lập kế hoạch chiến lược và xây dựng truy vấn
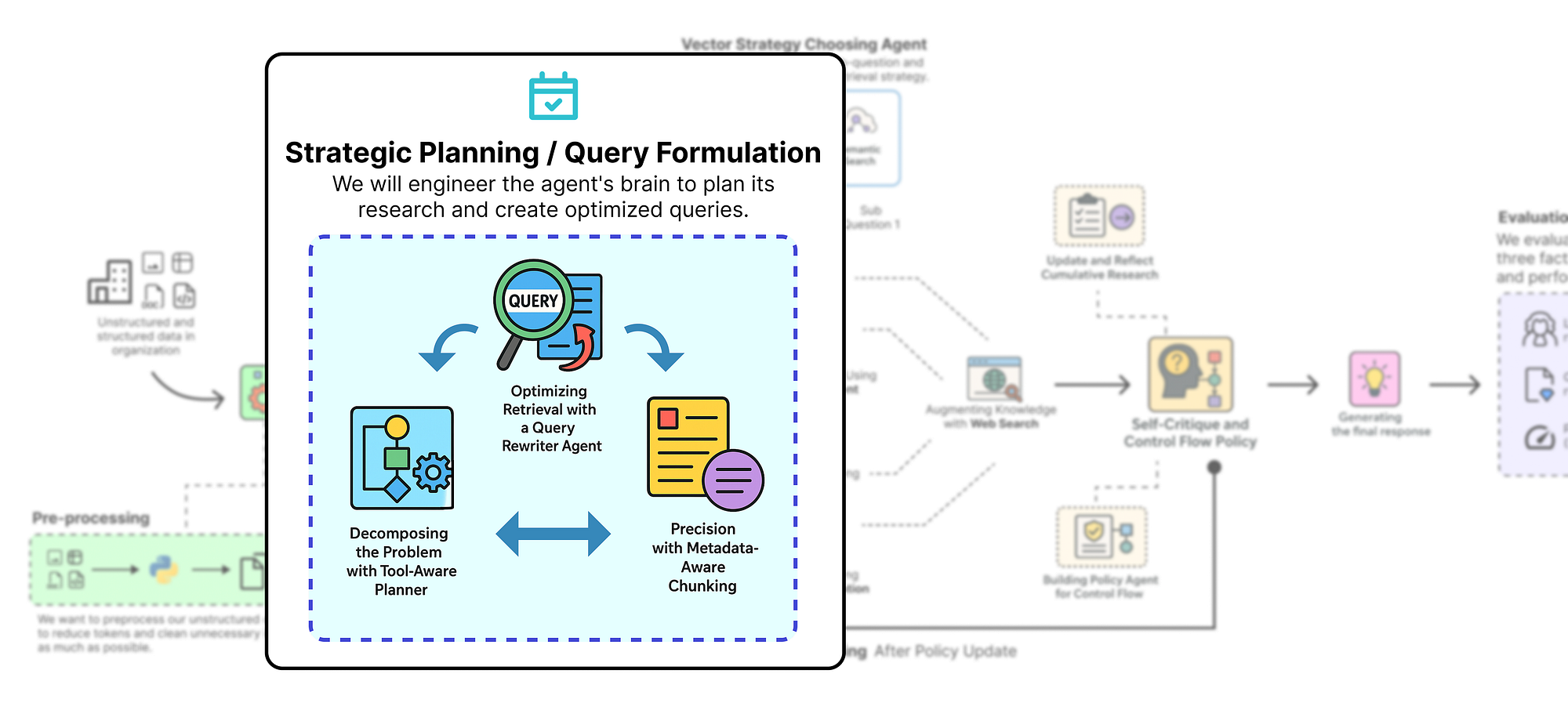
Với RAGState đã được định nghĩa, bây giờ chúng ta có thể xây dựng thành phần nhận thức đầu tiên và có thể nói là quan trọng nhất của agent: khả năng lập kế hoạch. Đây là nơi hệ thống của chúng ta thực hiện bước nhảy vọt từ một trình tìm nạp dữ liệu đơn giản thành một công cụ suy luận thực sự. Thay vì ngây thơ coi truy vấn phức tạp của người dùng như một tìm kiếm duy nhất, agent của chúng ta trước tiên sẽ tạm dừng, suy nghĩ và xây dựng một chiến lược nghiên cứu chi tiết, từng bước.
 Lập kế hoạch chiến lược (Tạo bởi Fareed Khan)
Lập kế hoạch chiến lược (Tạo bởi Fareed Khan)
Phần này được chia thành ba bước kỹ thuật chính:
- Planner nhận biết công cụ: Chúng ta sẽ xây dựng một agent được hỗ trợ bởi LLM có công việc duy nhất là phân rã truy vấn của người dùng thành một đối tượng
Plancó cấu trúc, quyết định công cụ nào sẽ sử dụng cho mỗi bước. - Agent viết lại truy vấn: Chúng ta sẽ tạo một agent chuyên biệt để chuyển đổi các câu hỏi phụ đơn giản của planner thành các truy vấn tìm kiếm hiệu quả cao, được tối ưu hóa.
- Phân mảnh nhận biết metadata: Chúng ta sẽ xử lý lại tài liệu nguồn của mình để thêm metadata cấp độ phần, một bước quan trọng mở ra khả năng truy xuất có độ chính xác cao, được lọc.
Phân rã vấn đề với planner nhận biết công cụ
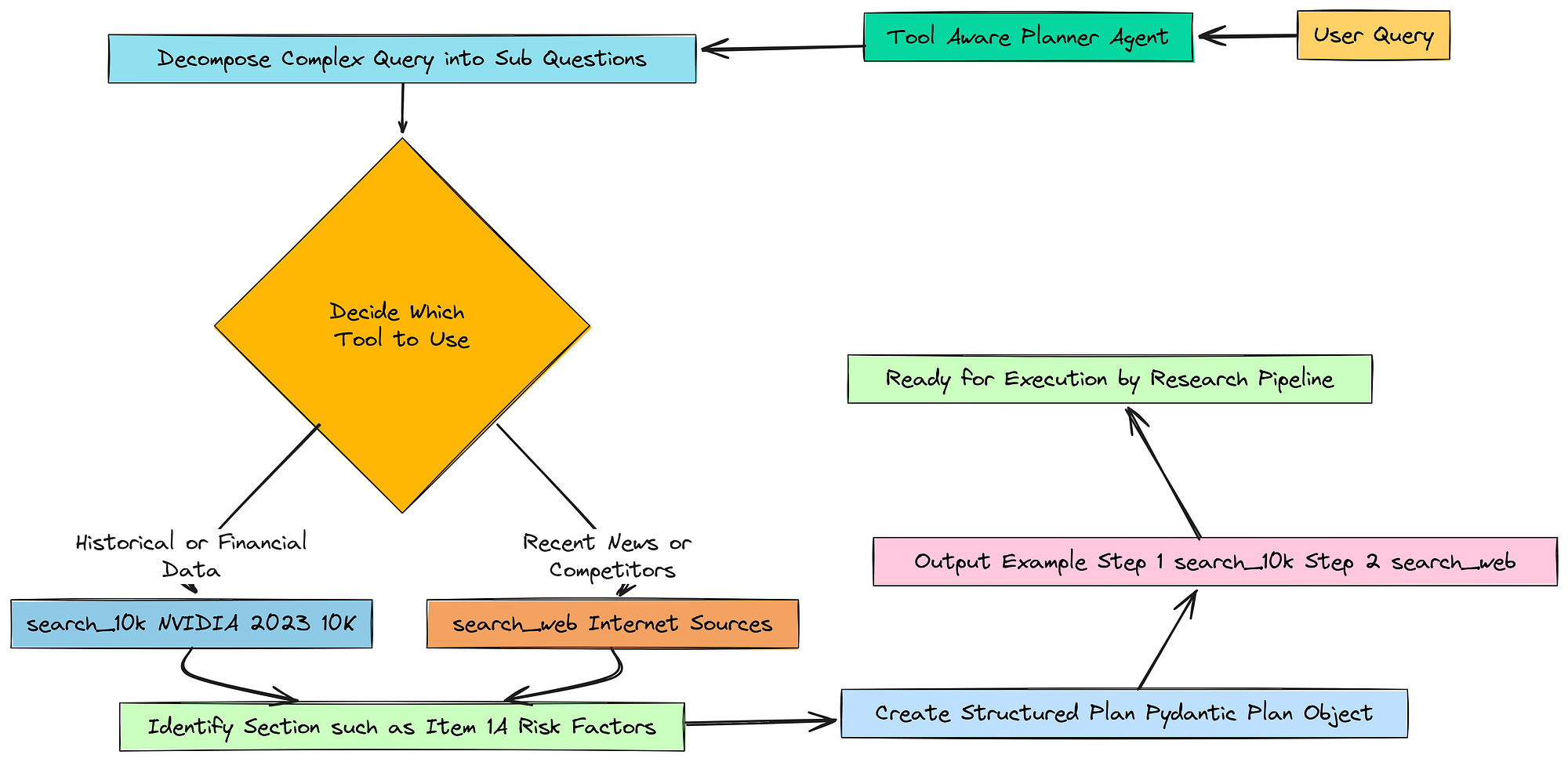
Về cơ bản, chúng ta muốn xây dựng bộ não của hoạt động. Điều đầu tiên bộ não này cần làm khi nhận được một câu hỏi phức tạp là tìm ra một kế hoạch hành động.
 Bước phân rã (Tạo bởi Fareed Khan)
Bước phân rã (Tạo bởi Fareed Khan)
Chúng ta không thể chỉ ném toàn bộ câu hỏi vào cơ sở dữ liệu của mình và hy vọng vào điều tốt nhất. Chúng ta cần dạy cho agent cách chia nhỏ vấn đề thành các phần nhỏ hơn, dễ quản lý.
Để làm điều này, chúng ta sẽ tạo một Planner Agent chuyên dụng. Chúng ta cần cung cấp cho nó một bộ hướng dẫn rất rõ ràng, hoặc một prompt, cho nó biết chính xác công việc của nó là gì.
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from rich.pretty import pprint as rprint
# Prompt hệ thống hướng dẫn LLM cách hành xử như một planner
planner_prompt = ChatPromptTemplate.from_messages([
("system", """Bạn là một chuyên gia lập kế hoạch nghiên cứu. Nhiệm vụ của bạn là tạo ra một kế hoạch rõ ràng, nhiều bước để trả lời một truy vấn phức tạp của người dùng bằng cách truy xuất thông tin từ nhiều nguồn.
Bạn có hai công cụ có sẵn:
1. `search_10k`: Sử dụng công cụ này để tìm kiếm thông tin trong báo cáo tài chính 10-K năm 2023 của NVIDIA. Đây là công cụ tốt nhất cho các sự kiện lịch sử, dữ liệu tài chính và các chính sách hoặc rủi ro đã nêu của công ty từ giai đoạn cụ thể đó.
2. `search_web`: Sử dụng công cụ này để tìm kiếm trên internet công cộng về tin tức gần đây, thông tin đối thủ cạnh tranh hoặc bất kỳ chủ đề nào không cụ thể cho báo cáo 10-K năm 2023 của NVIDIA.
Phân rã truy vấn của người dùng thành một loạt các câu hỏi phụ đơn giản, tuần tự. Đối với mỗi bước, hãy quyết định công cụ nào phù hợp hơn.
Đối với các bước `search_10k`, cũng hãy xác định phần có khả năng nhất của 10-K (ví dụ: 'Item 1A. Risk Factors', 'Item 7. Management's Discussion and Analysis...').
Điều quan trọng là phải sử dụng chính xác các tiêu đề phần được tìm thấy trong một báo cáo 10-K nếu có thể."""),
("human", "Truy vấn người dùng: {question}") # Truy vấn phức tạp, ban đầu của người dùng
])
Về cơ bản, chúng ta đang trao cho LLM một vai trò mới: một chuyên gia lập kế hoạch nghiên cứu. Chúng ta nói rõ cho nó biết về hai công cụ mà nó có (search_10k và search_web) và hướng dẫn nó khi nào nên sử dụng mỗi công cụ. Đây là phần "nhận biết công cụ".
Chúng ta không chỉ yêu cầu nó một kế hoạch mà còn yêu cầu nó tạo ra một kế hoạch ánh xạ trực tiếp đến các khả năng mà chúng ta đã xây dựng.
Bây giờ chúng ta có thể khởi tạo mô hình suy luận và kết nối nó với prompt của chúng ta. Một bước rất quan trọng ở đây là nói với LLM rằng đầu ra cuối cùng của nó phải ở định dạng của lớp Pydantic Plan của chúng ta. Điều này làm cho đầu ra có cấu trúc và có thể dự đoán được.
# Khởi tạo mô hình suy luận mạnh mẽ của chúng ta, như đã định nghĩa trong config
reasoning_llm = ChatOpenAI(model=config["reasoning_llm"], temperature=0)
# Tạo planner agent bằng cách nối prompt với LLM và hướng dẫn nó sử dụng đầu ra có cấu trúc 'Plan' của chúng ta
planner_agent = planner_prompt | reasoning_llm.with_structured_output(Plan)
print("Planner Agent nhận biết công cụ đã được tạo thành công.")
# Hãy kiểm tra planner agent với truy vấn phức tạp của chúng ta để xem đầu ra của nó
print("\n--- Đang kiểm tra Planner Agent ---")
test_plan = planner_agent.invoke({"question": complex_query_adv})
# Sử dụng rich's pretty print để hiển thị đối tượng Pydantic một cách sạch sẽ, dễ đọc
rprint(test_plan)
Chúng ta lấy planner_prompt, nối nó với reasoning_llm mạnh mẽ của chúng ta, và sau đó sử dụng phương thức .with_structured_output(Plan). Điều này cho LangChain biết sử dụng khả năng gọi hàm của mô hình để định dạng phản hồi của nó thành một đối tượng JSON hoàn toàn khớp với lược đồ Pydantic Plan của chúng ta. Điều này đáng tin cậy hơn nhiều so với việc cố gắng phân tích một phản hồi văn bản thuần túy.
Hãy xem đầu ra khi chúng ta kiểm tra nó với truy vấn thách thức của mình.
#### ĐẦU RA ####
Planner Agent nhận biết công cụ đã được tạo thành công.
--- Đang kiểm tra Planner Agent ---
Plan(
│ steps=[
│ │ Step(
│ │ │ sub_question="Các rủi ro chính liên quan đến cạnh tranh như đã nêu trong báo cáo 10-K năm 2023 của NVIDIA là gì?",
│ │ │ justification="Bước này cần thiết để trích xuất thông tin cơ bản về rủi ro cạnh tranh trực tiếp từ tài liệu nguồn theo yêu cầu của người dùng.",
│ │ │ tool='search_10k',
│ │ │ keywords=['cạnh tranh', 'yếu tố rủi ro', 'ngành công nghiệp bán dẫn', 'đối thủ cạnh tranh'],
│ │ │ document_section='Item 1A. Risk Factors'
│ │ ),
│ │ Step(
│ │ │ sub_question="Tin tức và phát triển gần đây trong chiến lược chip AI của AMD vào năm 2024 là gì?",
│ │ │ justification="Bước này yêu cầu tìm kiếm thông tin cập nhật, bên ngoài không có trong báo cáo 10-K năm 2023. Cần tìm kiếm trên web để có được các chi tiết mới nhất về chiến lược của AMD.",
│ │ │ tool='search_web',
│ │ │ keywords=['AMD', 'chiến lược chip AI', '2024', 'MI300X', 'bộ tăng tốc Instinct'],
│ │ │ document_section=None
│ │ )
│ ]
)
Nếu chúng ta nhìn vào đầu ra, bạn có thể thấy rằng agent không chỉ cho chúng ta một kế hoạch mơ hồ, nó đã tạo ra một đối tượng Plan có cấu trúc. Nó đã xác định chính xác rằng truy vấn có hai phần.
Tối ưu hóa truy xuất với agent viết lại truy vấn
Về cơ bản, chúng ta có một kế hoạch với các câu hỏi phụ tốt.
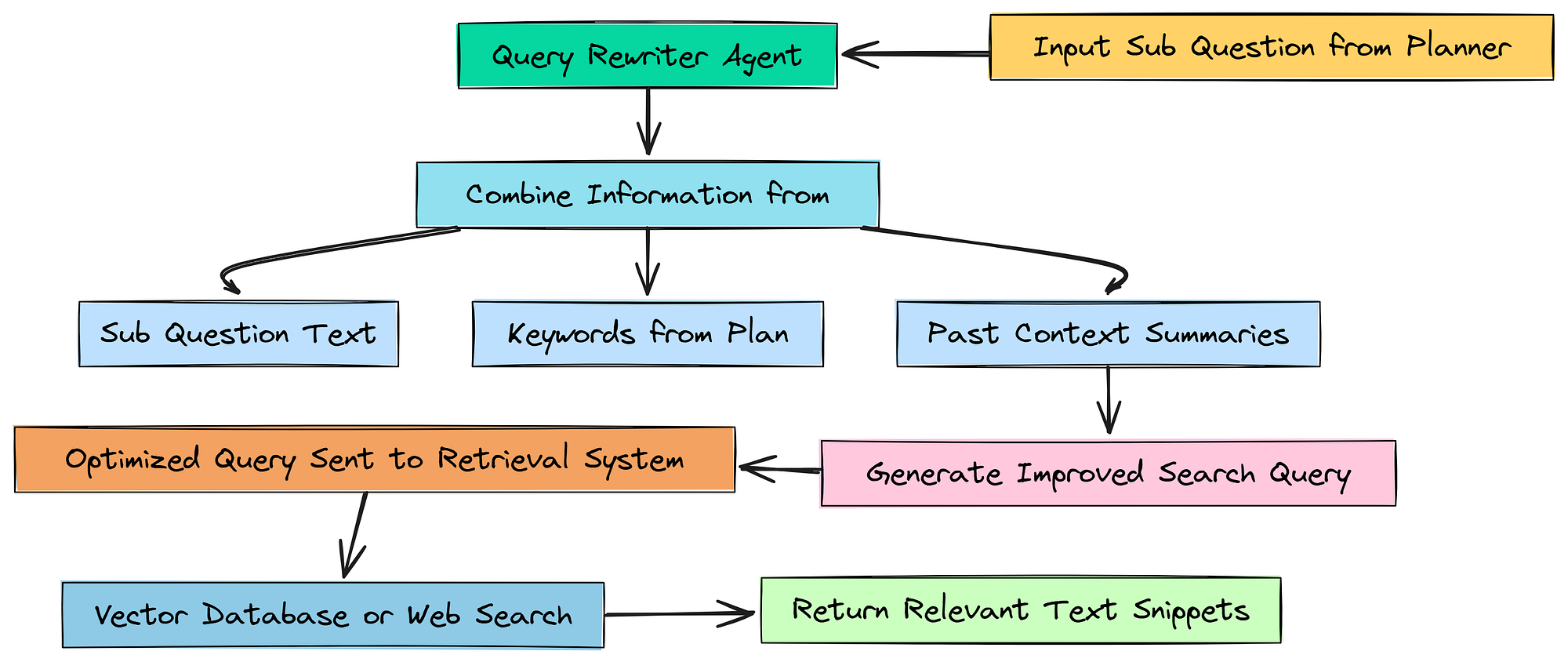
Nhưng một câu hỏi như "Rủi ro là gì?" không phải là một truy vấn tìm kiếm tốt. Nó quá chung chung. Các công cụ tìm kiếm, cho dù là cơ sở dữ liệu vector hay tìm kiếm web, hoạt động tốt nhất với các truy vấn cụ thể, giàu từ khóa.
 Agent viết lại truy vấn (Tạo bởi Fareed Khan)
Agent viết lại truy vấn (Tạo bởi Fareed Khan)
Để khắc phục điều này, chúng ta sẽ xây dựng một agent chuyên biệt nhỏ khác: Query Rewriter. Công việc duy nhất của nó là lấy câu hỏi phụ cho bước hiện tại và làm cho nó tốt hơn cho việc tìm kiếm bằng cách thêm các từ khóa và ngữ cảnh liên quan từ những gì chúng ta đã học được.
Đầu tiên, hãy thiết kế prompt cho agent mới này.
from langchain_core.output_parsers import StrOutputParser # Để phân tích đầu ra của LLM thành một chuỗi đơn giản
# Prompt cho agent viết lại truy vấn của chúng ta, hướng dẫn nó hoạt động như một chuyên gia tìm kiếm
query_rewriter_prompt = ChatPromptTemplate.from_messages([
("system", """Bạn là một chuyên gia tối ưu hóa truy vấn tìm kiếm. Nhiệm vụ của bạn là viết lại một câu hỏi phụ đã cho thành một truy vấn tìm kiếm hiệu quả cao cho cơ sở dữ liệu vector hoặc công cụ tìm kiếm web, sử dụng các từ khóa và ngữ cảnh từ kế hoạch nghiên cứu.
Truy vấn được viết lại phải cụ thể, sử dụng thuật ngữ có khả năng được tìm thấy trong nguồn mục tiêu (báo cáo tài chính 10-K hoặc các bài báo), và được cấu trúc để truy xuất các đoạn văn bản phù hợp nhất."""),
("human", "Câu hỏi phụ hiện tại: {sub_question}\n\nCác từ khóa liên quan từ kế hoạch: {keywords}\n\nNgữ cảnh từ các bước trước:\n{past_context}")
])
Về cơ bản, chúng ta đang yêu cầu agent này hoạt động như một chuyên gia tối ưu hóa truy vấn tìm kiếm. Chúng ta cung cấp cho nó ba mẩu thông tin để làm việc: sub_question đơn giản, keywords mà planner của chúng ta đã xác định, và past_context từ bất kỳ bước nghiên cứu nào trước đó. Điều này cung cấp cho nó tất cả nguyên liệu thô cần thiết để xây dựng một truy vấn tốt hơn nhiều.
Bây giờ chúng ta có thể khởi tạo agent này. Đó là một chuỗi đơn giản vì chúng ta chỉ cần một chuỗi làm đầu ra.
# Tạo agent bằng cách nối prompt với LLM suy luận của chúng ta và một bộ phân tích đầu ra chuỗi
query_rewriter_agent = query_rewriter_prompt | reasoning_llm | StrOutputParser()
print("Agent viết lại truy vấn đã được tạo thành công.")
# Hãy kiểm tra agent viết lại. Chúng ta sẽ giả vờ đã hoàn thành hai bước đầu tiên của kế hoạch.
print("\n--- Đang kiểm tra Agent viết lại truy vấn ---")
# Hãy tưởng tượng chúng ta đang ở bước tổng hợp cuối cùng cần ngữ cảnh từ hai bước đầu tiên.
test_sub_q = "Chiến lược chip AI năm 2024 của AMD có khả năng làm trầm trọng thêm các rủi ro cạnh tranh được xác định trong báo cáo 10-K của NVIDIA như thế nào?"
test_keywords = ['tác động', 'đe dọa', 'áp lực cạnh tranh', 'thị phần', 'thay đổi công nghệ']
# Chúng ta tạo một số "ngữ cảnh quá khứ" giả để mô phỏng những gì agent sẽ biết tại thời điểm này trong một lần chạy thực tế.
test_past_context = "Tóm tắt Bước 1: Báo cáo 10-K của NVIDIA liệt kê cạnh tranh gay gắt và thay đổi công nghệ nhanh chóng là những rủi ro chính. Tóm tắt Bước 2: AMD đã ra mắt bộ tăng tốc AI MI300X vào năm 2024 để cạnh tranh trực tiếp với H100 của NVIDIA."
# Gọi agent với dữ liệu thử nghiệm của chúng ta
rewritten_q = query_rewriter_agent.invoke({
"sub_question": test_sub_q,
"keywords": test_keywords,
"past_context": test_past_context
})
print(f"Câu hỏi phụ ban đầu: {test_sub_q}")
print(f"Truy vấn tìm kiếm được viết lại: {rewritten_q}")
Để kiểm tra điều này một cách đúng đắn, chúng ta phải mô phỏng một kịch bản thực tế. Chúng ta tạo một chuỗi test_past_context đại diện cho các bản tóm tắt mà agent đã tạo ra từ hai bước đầu tiên của kế hoạch. Sau đó, chúng ta cung cấp điều này, cùng với câu hỏi phụ tiếp theo, cho query_rewriter_agent của chúng ta.
Hãy xem kết quả.
#### ĐẦU RA ####
Agent viết lại truy vấn đã được tạo thành công.
--- Đang kiểm tra Agent viết lại truy vấn ---
Câu hỏi phụ ban đầu: Chiến lược chip AI năm 2024 của AMD có khả năng làm trầm trọng thêm các rủi ro cạnh tranh được xác định trong báo cáo 10-K của NVIDIA như thế nào?
Truy vấn tìm kiếm được viết lại: phân tích về cách chiến lược chip AI năm 2024 của AMD, bao gồm các sản phẩm như MI300X, làm trầm trọng thêm các rủi ro cạnh tranh đã nêu của NVIDIA như thay đổi công nghệ nhanh chóng và xói mòn thị phần trong ngành công nghiệp bán dẫn trung tâm dữ liệu và AI
Câu hỏi ban đầu dành cho một nhà phân tích, truy vấn được viết lại dành cho một công cụ tìm kiếm. Nó đã được gán các thuật ngữ cụ thể như “MI300X”, “xói mòn thị phần” và “trung tâm dữ liệu”, tất cả đều được tổng hợp từ các từ khóa và ngữ cảnh quá khứ.
Một truy vấn như thế này có nhiều khả năng truy xuất chính xác các tài liệu phù hợp, làm cho toàn bộ hệ thống của chúng ta chính xác và hiệu quả hơn. Bước viết lại này sẽ là một phần quan trọng trong vòng lặp agentic chính của chúng ta.
Độ chính xác với việc phân mảnh nhận biết metadata
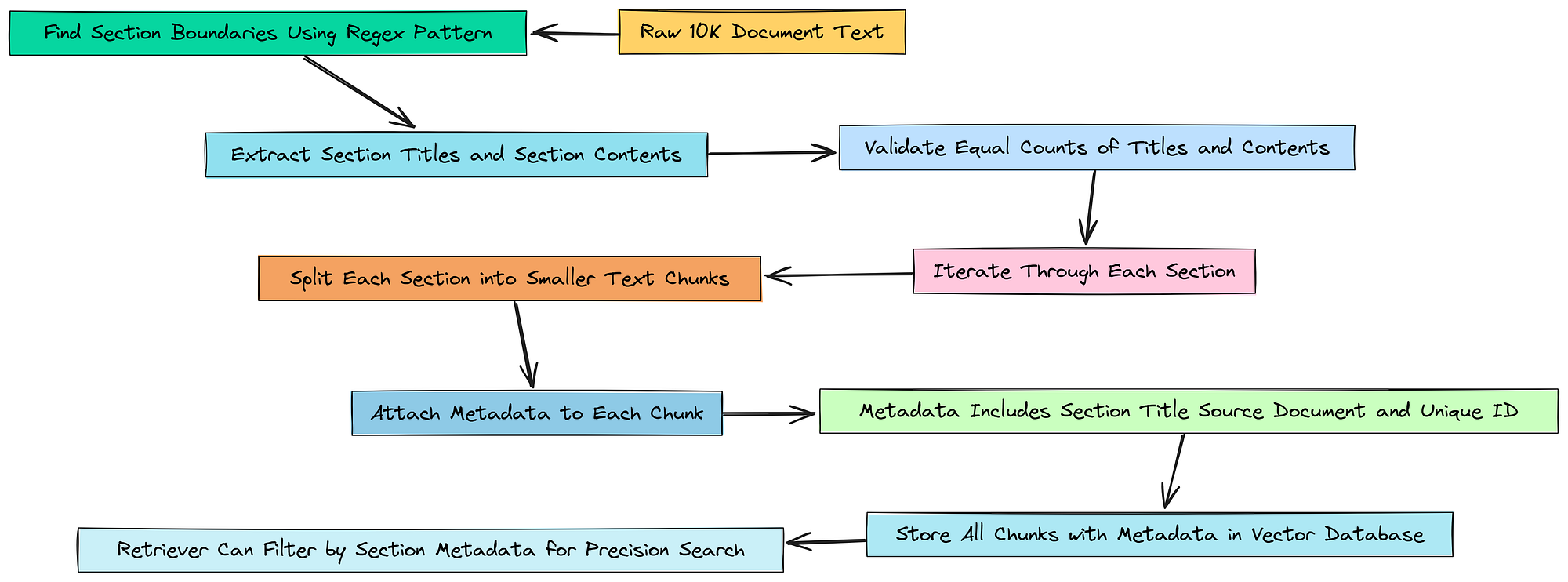
Về cơ bản, Planner Agent của chúng ta đang cho chúng ta một cơ hội tốt. Nó không chỉ nói tìm rủi ro, nó còn cho chúng ta một gợi ý: tìm rủi ro trong phần Item 1A. Risk Factors.
Nhưng hiện tại, retriever của chúng ta không thể sử dụng gợi ý đó. Vector store của chúng ta chỉ là một danh sách phẳng, lớn gồm 378 chunk văn bản. Nó không biết "phần" là gì.
 Phân mảnh nhận biết meta (Tạo bởi Fareed Khan)
Phân mảnh nhận biết meta (Tạo bởi Fareed Khan)
Chúng ta cần khắc phục điều này. Chúng ta sẽ xây dựng lại các chunk tài liệu của mình từ đầu. Lần này, đối với mỗi chunk chúng ta tạo ra, chúng ta sẽ thêm một nhãn hoặc một thẻ vào metadata của nó để cho hệ thống của chúng ta biết chính xác nó đến từ phần nào của báo cáo 10-K. Điều này sẽ cho phép agent của chúng ta thực hiện các tìm kiếm có độ chính xác cao, được lọc sau này.
Đầu tiên, chúng ta cần một cách để tìm ra vị trí bắt đầu của mỗi phần trong tệp văn bản thô của mình một cách tự động. Nếu chúng ta nhìn vào tài liệu, chúng ta có thể thấy một mẫu rõ ràng: mỗi phần chính bắt đầu bằng từ “ITEM” theo sau là một số, như “ITEM 1A” hoặc “ITEM 7”. Đây là một công việc hoàn hảo cho một biểu thức chính quy.
# Regex này được thiết kế để tìm các tiêu đề phần như 'ITEM 1A.' hoặc 'ITEM 7.' trong văn bản 10-K.
# Nó tìm kiếm từ 'ITEM', theo sau là một khoảng trắng, một số, một chữ cái tùy chọn, một dấu chấm, và sau đó bắt lấy văn bản tiêu đề.
# Các cờ `re.IGNORECASE | re.DOTALL` làm cho tìm kiếm không phân biệt chữ hoa chữ thường và cho phép '.' khớp với các dòng mới.
section_pattern = r"(ITEM\\s+\\d[A-Z]?\\.\\s*.*?)(?=\\nITEM\\s+\\d[A-Z]?\\.|$)"
Về cơ bản, chúng ta đang tạo ra một mẫu sẽ hoạt động như máy dò phần của chúng ta. Nó nên được thiết kế để đủ linh hoạt để bắt các định dạng khác nhau trong khi đủ cụ thể để không lấy nhầm văn bản.
Bây giờ chúng ta có thể sử dụng mẫu này để cắt tài liệu của mình thành hai danh sách riêng biệt: một chứa chỉ các tiêu đề phần, và một danh sách khác chứa nội dung trong mỗi phần.
# Chúng ta sẽ làm việc với văn bản thô được tải trước đó từ đối tượng Document của chúng ta
raw_text = documents[0].page_content
# Sử dụng re.findall để áp dụng mẫu của chúng ta và trích xuất tất cả các tiêu đề phần vào một danh sách
section_titles = re.findall(section_pattern, raw_text, re.IGNORECASE | re.DOTALL)
# Một bước dọn dẹp nhanh để loại bỏ bất kỳ khoảng trắng hoặc dòng mới thừa nào khỏi các tiêu đề
section_titles = [title.strip().replace('\\n', ' ') for title in section_titles]
# Bây giờ, sử dụng re.split để chia tài liệu tại mỗi điểm mà một tiêu đề phần xuất hiện
sections_content = re.split(section_pattern, raw_text, flags=re.IGNORECASE | re.DOTALL)
# Kết quả chia là một danh sách với các tiêu đề và nội dung trộn lẫn, vì vậy chúng ta lọc nó để chỉ lấy các phần nội dung
sections_content = [content.strip() for content in sections_content if content.strip() and not content.strip().lower().startswith('item ')]
print(f"Đã xác định được {len(section_titles)} phần tài liệu.")
# Đây là một kiểm tra quan trọng: nếu số lượng tiêu đề không khớp với số lượng khối nội dung, có điều gì đó đã sai.
assert len(section_titles) == len(sections_content), "Không khớp giữa tiêu đề và các phần nội dung"
Đây là một cách rất hiệu quả để phân tích một tài liệu bán cấu trúc. Chúng ta đã sử dụng mẫu regex của mình hai lần: một lần để có được một danh sách sạch tất cả các tiêu đề phần, và một lần nữa để chia văn bản chính thành một danh sách các khối nội dung. Câu lệnh assert cho chúng ta sự tự tin rằng logic phân tích của chúng ta là đúng đắn.
Được rồi, bây giờ chúng ta có các mảnh ghép: một danh sách các tiêu đề và một danh sách nội dung tương ứng. Bây giờ chúng ta có thể lặp qua chúng và tạo ra các chunk cuối cùng, giàu metadata của mình.
import uuid # Chúng ta sẽ sử dụng cái này để gán cho mỗi chunk một ID duy nhất, đây là một thực hành tốt
# Danh sách này sẽ chứa các chunk tài liệu mới, giàu metadata của chúng ta
doc_chunks_with_metadata = []
# Lặp qua nội dung của mỗi phần cùng với tiêu đề của nó bằng cách sử dụng enumerate
for i, content in enumerate(sections_content):
# Lấy tiêu đề tương ứng cho khối nội dung hiện tại
section_title = section_titles[i]
# Sử dụng cùng một bộ chia văn bản như trước, nhưng lần này, chúng ta chỉ chạy nó trên nội dung của phần
Theo dõi trên X